APR 15, 2024
Faster NLP with Deep Learning: Distributed Training

September 03, 2020
Training deep learning models for NLP tasks typically requires many hours or days to complete on a single GPU. In this post, we leverage Determined’s distributed training capability to reduce BERT for SQuAD model training from hours to minutes, without sacrificing model accuracy.
In this 2-part blog series, we outline tips and tricks to accelerate NLP deep learning model training across multiple GPUs, taking BERT for SQuAD model training time down from nearly 7 hours to under an hour. In this first post, we motivate the need for deep learning and distributed training in NLP, highlight the factors that matter most for effective distributed training, and provide supporting empirical results from a series of BERT fine-tuning experiments run in Determined. In part 2, we shift focus a level up from optimizing the distributed training loop and outline techniques to streamlining distributed data loading and model evaluation for the same NLP task.
The Seeds of Deep Learning for NLP
Neural language models like BERT and XLNet picked up headline-grabbing steam over the last couple of years. Why is this?
The machine learning algorithms for common NLP tasks like entity recognition and question answering generally require feature vectors as input. Typically, natural language inputs are represented as vectors, and from this point we train models to classify text, cluster documents, answer questions, and the like.1
A considerable amount of research over the past decade has demonstrated the importance of language modeling as a driver for the ultimate quality of the downstream NLP task models.2 The statistical language models of last century like bag-of-words and tf-idf effectively capped the state of the art well below “earth shattering” for many NLP tasks, particularly the AI-hard NLP tasks that captivate us. I remember first playing with the Babel Fish machine translation engine in the late 1990s and concluding that Skynet was a long way away — Babel Fish often felt more like a word-by-word dictionary lookup engine than a language understanding and translation AI.
The aforementioned cap has since lifted (arguably disappeared, for some NLP tasks) in ways that we experience every day when we search the web or talk to Alexa. NLP advancements exploded in 2018 as a new class of language models arrived: ELMo based on LSTMs, followed by BERT based on the transformer architecture.3 The New Idea of these language models is in their dependency on word context; whereas previous non-contextual word embeddings like word2vec and Glove encode a given word into exactly one vector, the Sesame Street models are designed to capture language nuance in ways that non-contextual word embeddings can’t by definition. (Can you spot an example in this sentence that would be problematic for word2vec, or are you seeing spots?)
Neural Language Model Training Cost
State-of-the-art language models are (sometimes astronomically) costly to train. Models like BERT and XLNet learn 100s of millions of parameters and the compute cost to train many neural language models from scratch is prohibitive for most organizations. As an example, XLNet required training for 5.5 days on 512 TPU v3’s. The cost for you to replicate this on GCP would be over $500,000.4 Language model complexity and training cost is only trending higher — OpenAI’s GPT-3 model, introduced in May 2020, learns 175 billion parameters and is estimated to have cost over $12M to train.
Thanks to the research community and the organizations backing language model research, high-quality pretrained models are freely available for anyone to use.5 Not only are the checkpoint bytes available, but the broader ML library ecosystem makes it straightforward to use these pretrained models in your framework of choice with a few lines of code. As a result, the aforementioned sequential transfer learning approach to NLP tasks is easy to implement on a reasonable budget. In our case, we will train a BERT model on the Stanford Question Answering Dataset (SQuAD) to produce a model that can extract answers to questions about a given passage. Each experiment required under $20 of compute cost to train on GCP, and we achieve high quality F1 scores in the 87-89% range. For comparison’s sake, human performance is 86.8%, and state of the art is 93%.6
Baseline Single GPU Training
Let’s start simple by training a BERT model for SQuAD on a single GPU. In this PyTorch example7, we use Hugging Face’s Transformers library’s pretrained model, featurization and data loading methods, and reference hyperparameters. Training for about 2 epochs on a single GPU yields an F1 score of 88.4% on the validation dataset. Not bad at all… but it took well over 7 hours to train. That’s a long time to wait for results, and this is only one well-trodden benchmark NLP task with fixed hyperparameters. If you or your team need to train on more data, tune hyperparameters, train models for other NLP tasks, or develop and debug models for custom downstream tasks, needing a day or longer to train a model would significantly hamper progress.
Dividing and Conquering
In the remainder of this post, we are going to divide and conquer model training with Determined’s distributed training capability, so that we can get the same model performance in a fraction of the wall clock time. In the process, we’ll surface the key factors affecting scaling performance and offer practical guidance for effective distributed training.
Thanks to Determined’s standardized model paradigm, distributing your training workload across multiple GPUs (potentially on multiple machines) requires no code changes. Every result that follows, whether leveraging 2 GPUs on a single machine or 16 GPUs across multiple machines, only required a configuration change.
Let’s see how we can train the same model above in a lunch break rather than a full workday, by utilizing distributed training on Determined. In this blog, we focus on distributing the training loop. In part 2, we will focus on other components of the training workflow that impact overall runtime, namely data loading and validation. To that end, the following wall clock times are net of data loading and validation.8
The Results
The following graph and table show wall clock training time as we scale from 1 to 8 NVIDIA K80 GPUs,9 all on a single machine. For these experiments, we fixed both the per-GPU batch size and the total number of epochs to train.
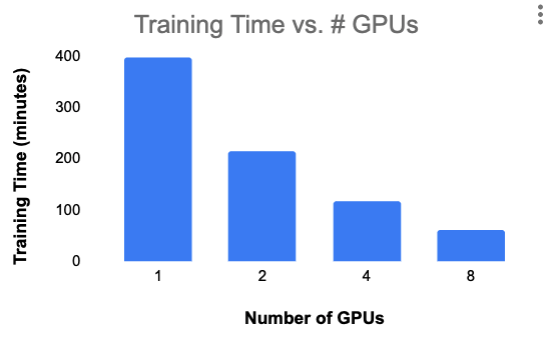
| # GPUs | Training Time (minutes) | Per-GPU Scaling Efficiency |
|---|---|---|
| 1 | 399 | 1.00 |
| 2 | 214 | 0.93 |
| 4 | 118 | 0.85 |
| 8 | 61 | 0.82 |
This is a decent initial result — we aren’t achieving linear scaling, but our scaling efficiency remains above 80%, and also we managed to get wall clock training time for the BERT SQuAD model down to an hour. Validation set F1 was 87-88% for all four experiments.
Doing Better
In our results above, there is a clear downward trend in scaling efficiency as we increase the degree of training parallelism. What’s going on there? Maybe we can live with the results at this scale, but what if we had a much heavier-weight training workload that we wanted to distribute across 64 GPUs? The trend is not playing in our favor.
A natural theory for what might be happening is that training is communication-bound. To distribute training over 8 GPUs, we divide our training dataset into 8 shards, independently train 8 models (one per GPU) for one batch, and then aggregate and communicate gradients so that all models have the same weights. Then we repeat this process of forward & backward pass followed by gradient aggregation, for every batch.10 As we discuss in our blog here and in our product documentation here, communication-reducing techniques like large batch training can help to reduce wall clock training time. Such techniques are particularly promising when GPUs are connected via PCI-E as opposed to higher-bandwidth (yet more expensive) NVLink.11
Let’s see if this theory plays out for our model. With Determined, you can adjust your per-slot batch size with a configuration change, though bear in mind that even small increases can quickly exhaust GPU memory because the intermediate state needed for the forward and backward pass scale with the size of the model and are linearly dependent on the batch size. Instead, we will keep our GPU memory requirements moderate so that we can run on lower cost NVIDIA K80s. We accomplish this by leveraging a Determined distributed training optimization that reduces both inter-GPU communication and per-GPU memory requirements. This aggregation frequency configuration option specifies the number of forward and backward passes to perform before communicating gradient updates across GPUs. In the following table, we see that increasing our aggregation frequency definitely helps runtime:
| Aggregation Frequency | Wall Clock Time Savings (minutes) | Validation F1 |
|---|---|---|
| 2 | 14 | 87.3 |
| 10 | 24 | 85 |
| 100 | 31 | 52.1 |
That’s great — if we can cut 31 minutes off of training time, our per-GPU scaling efficiency goes from 0.93 to a perfect 1. I left something out though — for the 3 rows above, our validation dataset F1 scores are 87.3%, 85%, and (gulp) 52.1%, respectively.
So close, and yet so far. What is happening here? Large batch stochastic gradient descent doesn’t always “just work”; in particular, it’s difficult to find the learning rate sweet spot in this setting. Sometimes, the Linear Scaling Rule works, where if we multiple the batch size by k, we also multiply the (previously tuned) learning rate by k. In our case, using the AdamW optimizer, linear scaling did not help at all; in fact, our F1 scores were even worse when applying the Linear Scaling Rule. Learning rate warmup strategies can also help, where smaller learning rates are used early in large-batch training. In our experience, though, the RAdam optimizer is a better bet that performs robustly for large batch training without the need for extensive learning rate tuning. When we swap in this RAdam implementation, our results look much better:
| Aggregation Frequency | Wall Clock Time Savings (minutes) | Validation F1 |
|---|---|---|
| 10 | 19 | 87.7 |
| 100 | 21 | 83.8 |
In this case, we can see that even a fairly aggressive aggregation frequency of 10 maintains validation performance and gives us perfect training scaling in going from 1 to 2 GPUs. The example with aggregation frequency 100 is included to show that even though wall clock time speedup has reached the point of diminishing returns, RAdam is robust enough to perform reasonably well even in extreme circumstances. Realistically, we’d recommend testing aggregation frequencies under 16 to improve wall clock training time while not sacrificing model performance.
Supercharged Multi-Machine Training
We have come a long way, employing Determined’s distributed training capability to reduce BERT for SQuAD training time from nearly 7 hours on a single GPU to under an hour on 8 GPUs attached to a single machine.
What can we do to further reduce training time, especially given the fact that 8 GPUs is the max allowed for a single instance on GCP? With Determined, model developers can scale out to multi-machine training just as easily as multi-GPU training on a single machine. This is particularly valuable when baseline single GPU training time takes days to weeks.
In the case of training BERT for SQuAD, when scaling out training to 16 GPUs across two instances, we reduced training time even further to 30 minutes. Compared to our first single-GPU training job, we achieve per-GPU scaling efficiency of 0.83.
It’s worth noting that as we scaled out to multiple machines, we became even more communication-bound, to the point that training time on 16 GPUs would actually be greater than the training time on 8 GPUs on a single machine if we held the effective batch size constant. By increasing the aggregation frequency to just 2, and using the RAdam optimizer, we scale much better and still achieve an F1 score of 87 on the validation dataset.
What’s Next?
In this post, we distributed BERT for SQuAD model training to cut training time down from nearly 7 hours to an impressive 30 minutes. While we optimized for and reported on the training loop for this post, in the next post we will go outside of the training loop and further optimize model training for the distributed setting. We’ll leverage some coming-soon product enhancements to make this happen, so stay tuned for the next installment.
Hopefully this post has shown that distributed training with Determined on a real-world NLP transfer learning use case is both easy and highly valuable. If you’re ready for your training jobs to complete over lunch rather than overnight, give it a try and give me a shout to let me know how it goes. Happy training!
-
This is the sequential transfer learning (STL) paradigm, where a (usually costly) pretraining task is completed once, and the resulting pretrained model is the starting point from which we train models for downstream adaptation tasks. This blog offers a great explanation of STL and other flavors of transfer learning in NLP. ↩
-
A Survey of the State-of-the-Art Language Models up to Early 2020 ↩
-
Other Sesame Street characters have since joined the NLP party, with Big Bird most recently being introduced with a specialization in long word sequences. ↩
-
132 hours, times $8 per TPU hour (the cost at the time of writing), times 512. ↩
-
The current state of the art uses a different model: SA-Net on Albert (ensemble). ↩
-
August 2023 update: The original BERT example has been replaced with an ALBERT example. ↩
-
Specifically, in order to report on model effectiveness, we only run a single validation pass at the end of training. Training time reported in this blog is the duration observed from the time we train our first batch to the time that we begin the validation pass. ↩
-
The GPUs were connected via PCI-E. GCP offers NVIDIA Tesla V100s connected via NVLink, though for more than 5x the cost per GPU at the time of writing this blog. ↩
-
This is a slight simplification. Determined’s distributed training implementation performs wait-free backpropagation, meaning that gradient updates are communicated layer by layer. This enables communication to happen in parallel with the backwards pass. ↩
-
This comparison reports NVLink bandwidth ~3x greater than PCI-E. ↩