In defense of weight-sharing for neural architecture search: an optimization perspective


July 17, 2020
This collaborative work between CMU and Determined AI is cross-listed on the ML@CMU Blog.
Neural architecture search (NAS) – selecting which neural model to use for your learning problem – is a promising but computationally expensive direction for automating and democratizing machine learning. The weight-sharing method, whose initial success at dramatically accelerating NAS surprised many in the field, has come under scrutiny due to its poor performance as a surrogate for full model-training (a miscorrelation problem known as rank disorder) and inconsistent results on recent benchmarks. In this post, we give a quick overview of weight-sharing and argue in favor of its continued use for NAS. To do so, we will consider a simple optimization formulation that reveals the following key takeaways:
- The fact that weight-sharing works should not really be too surprising to a community that embraces non-convex optimization of over-parameterized models.
- Rank disorder is not a concern for most weight-sharing methods, since we care about obtaining high-quality architectures rather than a ranking of them.
- The sometimes-poor performance of weight-sharing is a result of optimization issues that can be fixed while still using weight-sharing. We propose such a fix – a geometry-aware exponentiated algorithm (GAEA) – that is applicable to many popular NAS methods and achieves state-of-the-art results across several settings.
A brief history of NAS with weight-sharing
NAS is usually formulated as a bilevel optimization problem in which we are searching over some architecture domain \(A\) for the architecture \(a\in A\) that achieves the lowest validation loss \(\ell_V(w_a,a)\) after training weights \(w_a\) that minimize the training loss \(\ell_T(\cdot,a)\):
\[\min_{a\in A}~~\ell_V(w_a,a)\qquad\textrm{s.t.}\qquad w_a\in\arg\min_{w\in\mathbb R^d}~~\ell_T(w,a)\]First-generation NAS methods were astronomically expensive due to the combinatorially large search space, requiring the training of thousands of neural networks to completion. Then, in their 2018 ENAS (for Efficient NAS) paper, Pham et al. introduced the idea of weight-sharing, in which only one shared_ set of model parameters \(w\in\mathbb R^d\) is trained for all architectures. The validation losses \(\ell_V(w,a)\) of different architectures \(a\in A\) computed using these shared weights are then used as estimates of their validation losses \(\ell_V(w_a,a)\) using standalone weights \(w_a\) (i.e. weights trained individually for each architecture by solving the inner optimization problem above). Because only one set of parameters has to be trained, weight-sharing led to a massive speedup over earlier methods, reducing search time on CIFAR-10 from 2,000-20,000 GPU-hours to just 16. Of great surprise to many was that the validation accuracies \(\ell_V(w,a)\) computed using shared weights \(w\) were sufficiently good surrogates for \(\ell_V(w_a,a)\), meaning ENAS was able to find good models cheaply. We will see that this correlation is actually a sufficient but not necessary condition for weight-sharing to do well and that weight-sharing’s overall success is less surprising than initially thought.
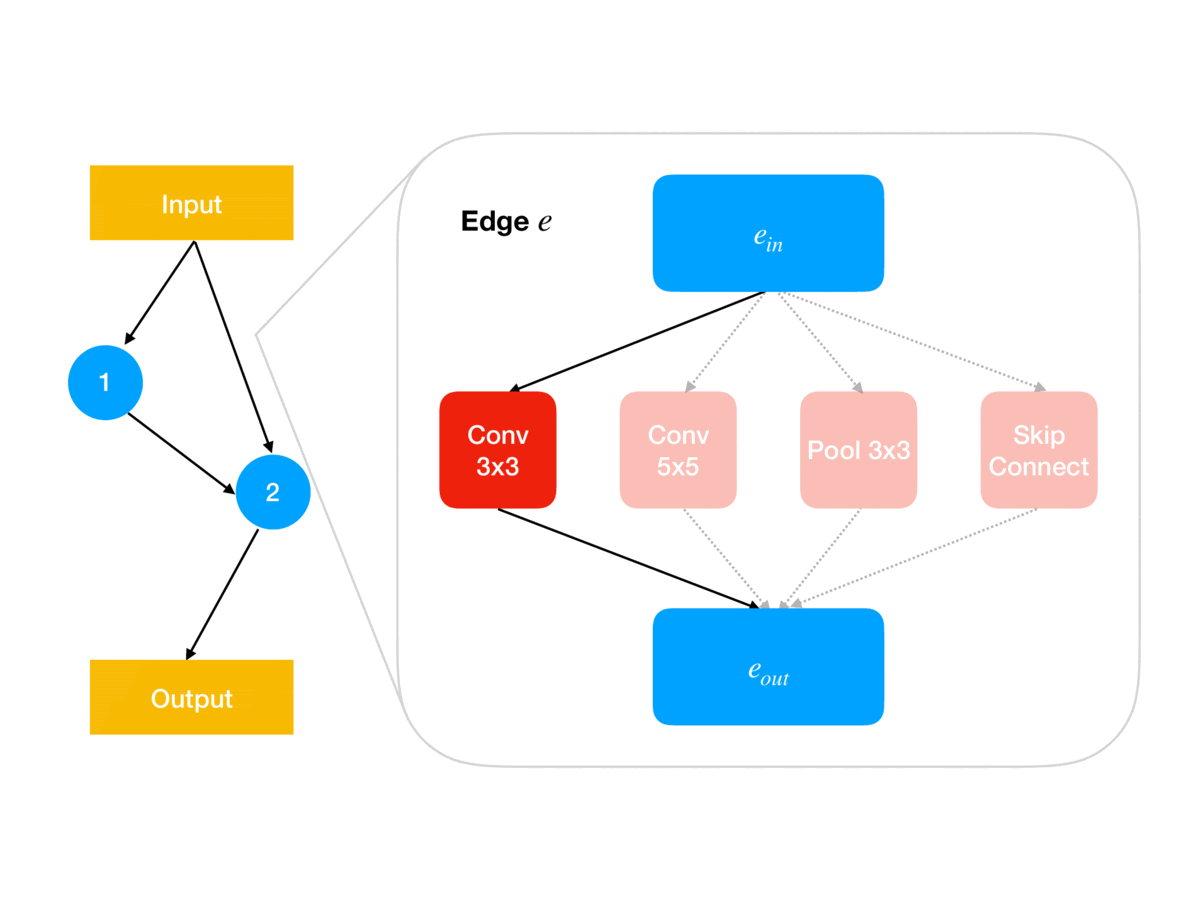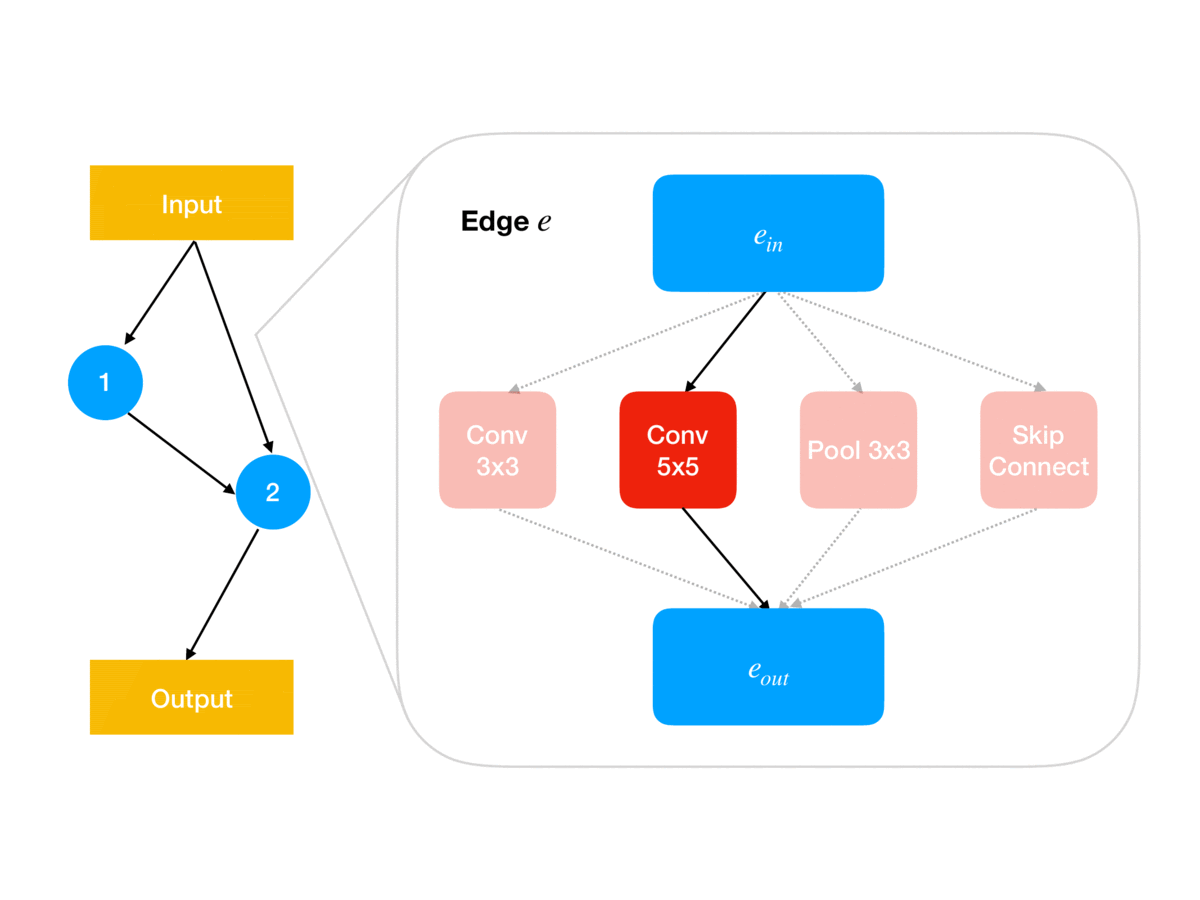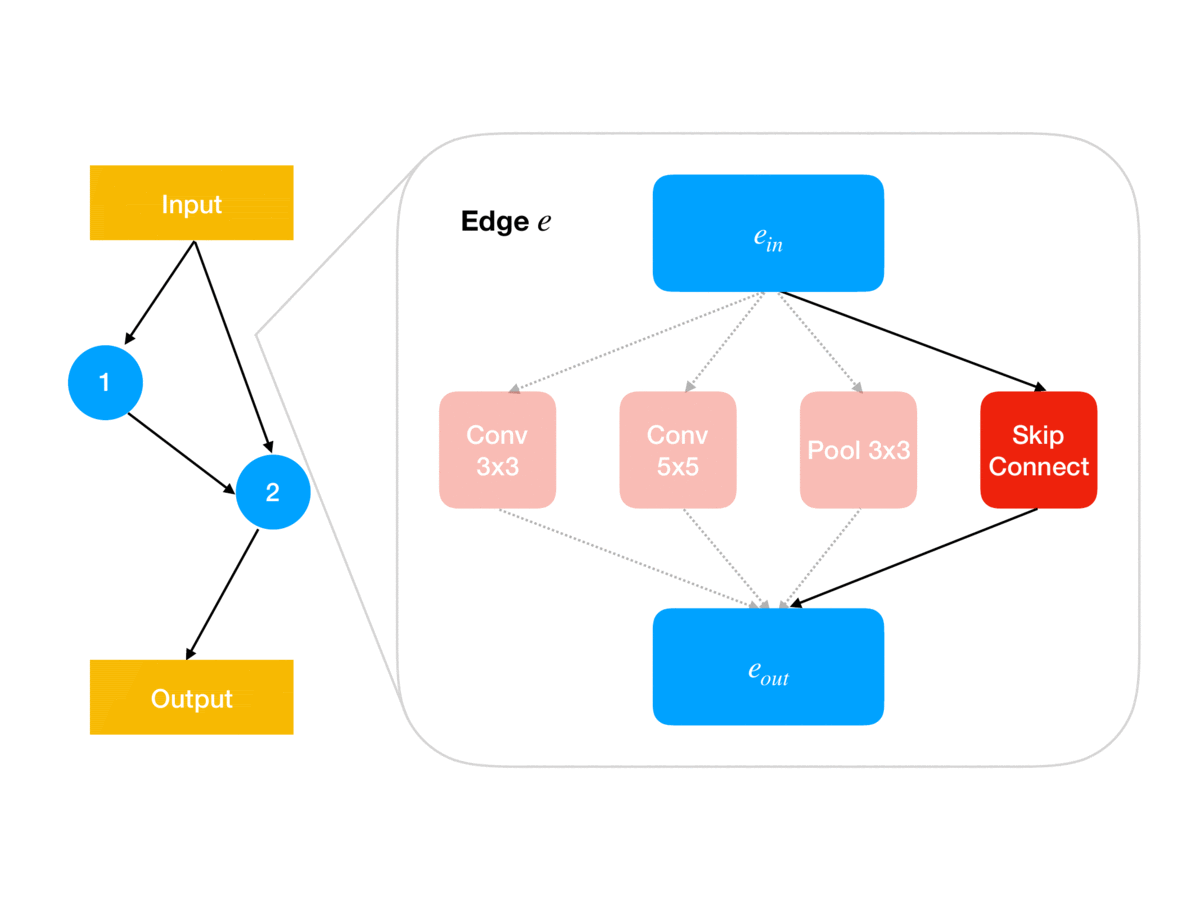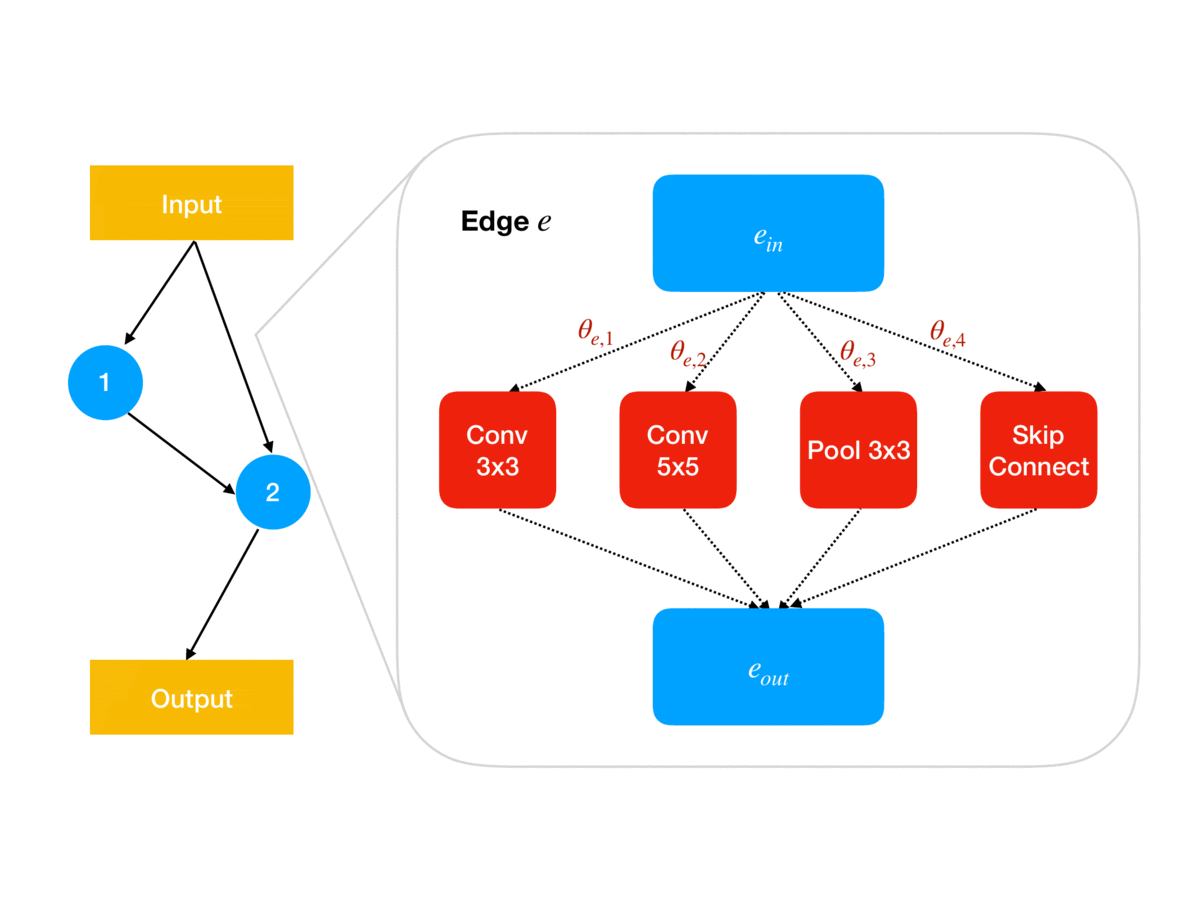
Following the ENAS breakthrough, several simpler methods such as DARTS and GDAS were proposed in which the categorical architecture decisions (e.g. for each network edge \(e\in E\), which of some fixed set of operations \(O\) to use at \(e\)) are relaxed into continuous parameters \(\theta\in\Theta\) (e.g. so \(\Theta\) is a product of \(\vert E\vert\) simplices of size \(\vert O\vert\)). As animated in Figure 1, these architecture parameters govern the architecture used for updating the shared weights using the gradient of the training loss; for example, in DARTS, \(\theta_{e,o}\) determines the weighting in the weighted sum of operations output by edge \(e\) in the network. Together, this parameterization leads to a continuous relaxation of the earlier bilevel problem:
\[\min_{\theta\in\Theta}~~\ell_V(w_\theta,\theta)\qquad\textrm{s.t.}\qquad w_\theta\in\arg\min_{w\in\mathbb R^d}~~\ell_T(w,\theta)\]Since \(\Theta\) is a constrained subset of \(\mathbb R^{\vert E\vert \vert O\vert}\), DARTS and GDAS avoid simplex projections by instead re-parameterizing to “logit” parameters \(\alpha\in\mathbb R^{\vert E\vert \vert O\vert}\), with \(\theta=\textrm{Softmax}(\alpha)\) defined as
\[\theta_{e,o}=\frac{\exp(\alpha_{e,o})}{\sum_{o'\in O}\exp(\alpha_{e,o'})}\]The relaxed optimization problem can then be approximated via the following alternating gradient update scheme (here \(\eta>0\) is a stepsize):
\[\begin{aligned} 1.\quad&\texttt{initialize }w^{(0)}\in\mathbb R^d,\alpha^{(0)}\in\mathbb R^{\vert E\vert \vert O \vert}\\ 2.\quad&\texttt{for iteration }i=0,\dots,n-1\texttt{ do:}\\ 3.\quad&\quad w^{(i+1)}\gets w^{(i)}-\eta\nabla_w\ell_T(w^{(i)},\alpha^{(i)})\\ 4.\quad&\quad \alpha^{(i+1)}\gets\alpha^{(i)}-\eta\nabla_\alpha\ell_V(w^{(i+1)},\alpha^{(i)})\\ 5.\quad &\texttt{return }\theta=\textrm{Softmax}(\alpha^{(n)}) \end{aligned}\]Note that at the end of search, we need to recover a discrete architecture \(a\in A\) from the architecture weights \(\theta\); in DARTS this is done in a pruning step that simply chooses the highest-weighted operations. This post-hoc pruning is a source of error that our method, GAEA, ameliorates, as we discuss later.
A further simplification, and perhaps the most striking example of using shared weights as surrogates for standalone weights, is the Random Search with Weight-Sharing (RS-WS) method, in which the shared parameters are optimized by taking gradient steps using architectures sampled uniformly at random from the search space. Despite not even updating architecture parameters, RS-WS achieved competitive and, in some cases, state-of-the-art results.
Should we be using weight-sharing?
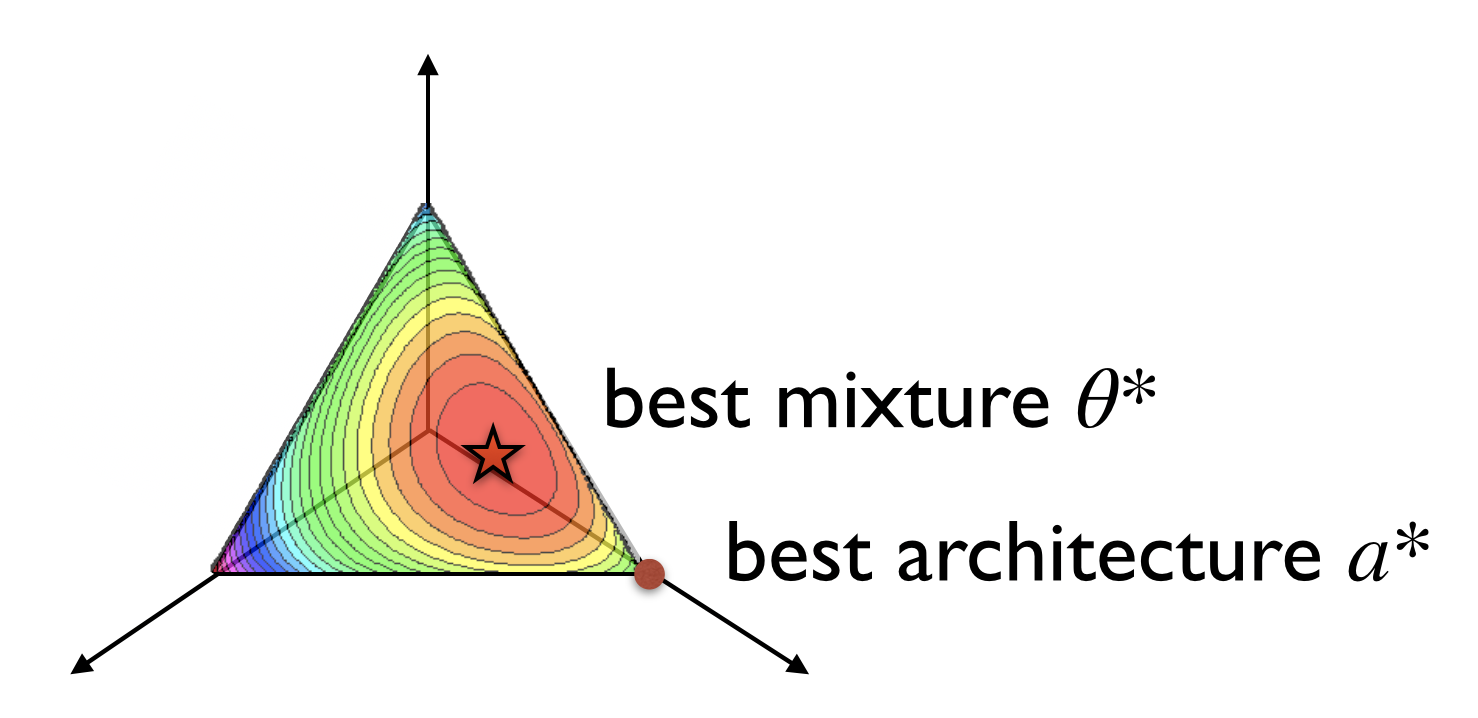
More recently, weight-sharing has come under increased scrutiny: does sharing weights between models really accelerate NAS? Can it preclude the recovery of optimal architectures? In particular, several papers have observed the issue of rank disorder, which is when the shared-weight performance of architectures does not correlate well with their stand-alone performance; this issue is illustrated in the figure below. Rank disorder is a problem for methods such as RS-WS that rely on the shared-weights performance to rank architectures for evaluation, as it will cause them to ignore networks that achieve high accuracy when their parameters are trained without sharing.
![]()
This skepticism has been reinforced by recent cases where well-known weight-sharing methods have performed poorly; in particular, DARTS was found to overfit to the upper-level validation set in a recent robustness evaluation, and both GDAS and DARTS were outperformed by standard hyperparameter optimization methods on NAS-Bench-201 given a similar time budget. Here DARTS had especially poor performance, converging to architectures consisting of only identity maps (skip-connections).
Given the questions raised about weight-sharing and recent poor results, is it time to rethink its use? In the next section, we answer in the negative by showing that (a) correlation of the performance of the weight-sharing “supernet” with that of fully trained models is a sufficient but not necessary condition for weight-sharing to work, i.e. we need not be afraid of rank disorder, and (b) obtaining high-quality architectural solutions using weight-sharing mostly comes down to regularization and optimization, two well-understood aspects of machine learning. In the last section we quickly highlight some recent work on regularization in NAS before presenting our own work looking at the optimization side.
Vanilla weight-sharing is just empirical risk minimization
Weight-sharing is made possible by the fact that architecture parameters, unlike hyperparameters such as regularization and stepsize, directly affect the loss function, in that changing from one architecture \(a\in A\) to a different architecture \(a'\in A\) causes a change in the loss from \(\ell(w,a)\) to \(\ell(w,a')\), as in the latter case a different function is being used for prediction. On the other hand, changing the stepsize setting would not change the loss unless the weights were also changed by training \(w\) using the new stepsize; this would mean the weights were no longer shared by different hyperparameter settings.
In fact, we can use the fact that architecture parameters can be subsumed as parameters of a supernet to pose NAS with weight-sharing as empirical risk minimization (ERM) over an extended class of functions encoded by both weights \(w\in\mathbb R^d\) and architecture parameters \(\theta\in\Theta\):
\[\min_{w\in\mathbb R^d,\theta\in\Theta}\ell_T(w,\theta)\]Most (but not all) empirical work on NAS uses the bilevel formulation described earlier rather than solving this single-level ERM problem. However, we believe ERM should be the baseline object of study in NAS because it is better understood statistically and algorithmically; the more common bilevel optimization can be viewed as a (possibly critical) method of regularizing by splitting the data.
The single-level formulation makes clear that, rather than rank disorder, NAS can fail for either of the usual reasons ERM fails: unsuccessful optimization or poor generalization. For example, these respective failures can largely explain the issues faced by DARTS on NAS-Bench-201 and NAS-Bench-1Shot1 that were discussed above. Of course, it is not surprising that supernets might face optimization and generalization issues, since they are non-convex and over-parameterized models; however, NAS practitioners are usually very comfortable training regular deep nets, which are also non-convex and have almost as many parameters. One major difference is that, in the latter case, we have had many years of intensive effort designing regularization schemes and optimization algorithms; if we were to dedicate a similar amount of NAS research to these two issues, then perhaps we would be no more afraid of weight-sharing than we are of training standard deep nets.
One caveat to this discussion is that NAS has the additional challenge of recovering discrete architectures from continuously-relaxed architecture weights. The optimization scheme we propose next ameliorates this issue by promoting sparse architectural parameters in the first place.
Fixing differentiable NAS with weight-sharing: a geometry-aware approach
Our discussion above reduces the problem of designing NAS methods to that of designing good regularization and optimization schemes for the supernet. There has been a good amount of recent work on better regularization schemes for the supernet, including partial channel connections, penalizing the Hessian of the validation loss, and the bilevel formulation itself; we thus focus instead on improving the optimization scheme, which we do with our geometry-aware exponentiated algorithm (GAEA).
As usual, we want an optimization method that can converge to a better solution faster. In the case of weight-sharing NAS, a high-quality solution will not only have good generalization but also induce sparse architecture weights \(\theta\in\Theta\), which recall is related to the optimized parameters \(\alpha\in\mathbb R^{\vert E\vert \vert O\vert}\) via a softmax. We expect sparse architecture parameters to be better because, as discussed earlier, the architecture parameters are rounded in a post-processing step to derive the final discrete architecture.
In order to achieve this, we use exponentiated gradient descent to directly optimize over the elements \(\theta\in\Theta\) instead of over unconstrained values \(\alpha\in\mathbb R^{\vert E\vert \vert O \vert}\). The update scheme replaces subtracting the gradient w.r.t. \(\alpha\) (line 4 in the pseudo-code) with element-wise multiplication by the negative exponentiated gradient w.r.t. \(\theta\) (4.a), followed by projections to the simplices comprising \(\Theta\) (4.b):
\[\begin{align*} 4.a\quad&\qquad\tilde\theta\gets\theta^{(i)}\odot\exp\left(-\eta\nabla_\theta\ell(w^{(i+1)},\theta^{(i)})\right)\\ 4.b\quad&\qquad\texttt{for }e\in E,o\in O\texttt{ do: }\theta_{e,o}^{(i+1)}\gets\frac{\tilde\theta_{e,o}}{\sum_{o'\in O}\tilde\theta_{e,o'}} \end{align*}\]Note that each iteration is roughly as expensive as in SGD.
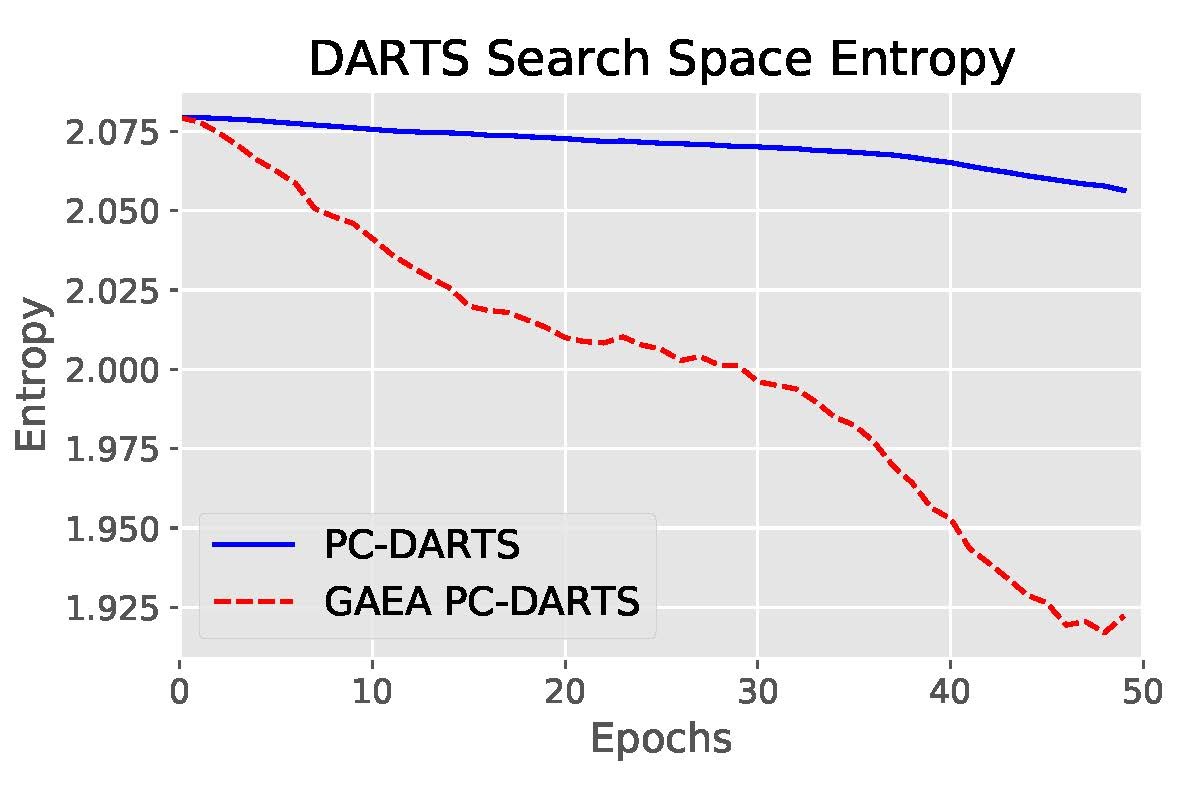
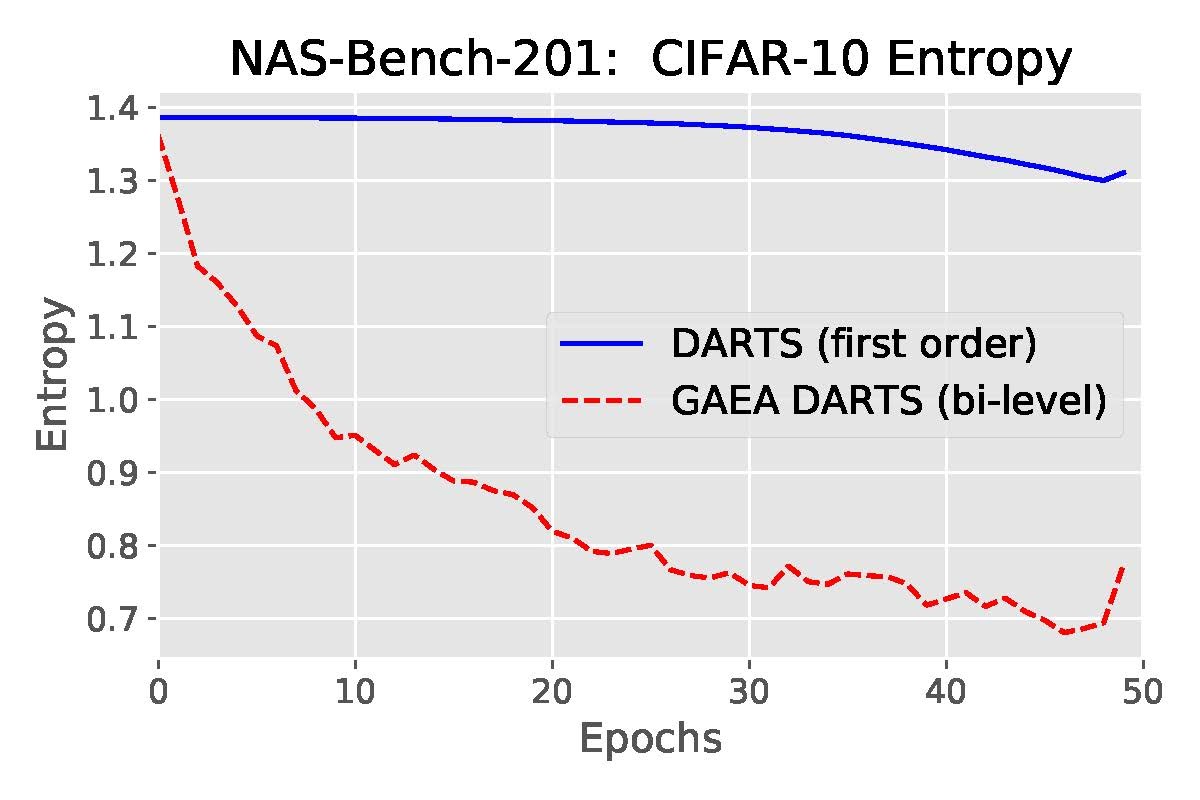
For convex problems, exponentiated gradient is known to be well-suited for the simplex geometry, with iteration complexity depending only logarithmically on the size \(k\) of the simplex, rather than the \(\mathcal O(k)\) dependence of gradient descent. Under the mirror descent view of this result for linear prediction (video link), the improvement stems from the implicit regularizer encouraging larger updates when far away from a sparse target solution. For our non-convex problem, we obtain a similar guarantee by extending recent mirror descent results of Zhang & He to show that alternating the exponentiated update to the architecture parameters with SGD updates to the shared-weights yields an \(\varepsilon\)-stationary-point in \(\mathcal O(\log k/\varepsilon^2)\) iterations. We also show experimentally in Figure 4 that this approach encourages sparser solutions than DARTS and PC-DARTS.
 |
 |
Our GAEA approach, which is applicable to any method using the softmax formulation described earlier (this includes DARTS, GDAS, PC-DARTS, and others), can be summarized in two simple steps:
- Replace architecture weights \(\alpha\) passed to the softmax with weights \(\theta\) lying directly on the architecture decision simplices.
- Use the exponentiated gradient scheme (4.a & 4.b) to update these architecture weights \(\theta\).
Empirical Evaluation of GAEA
 |
 |
 |
|
|---|---|
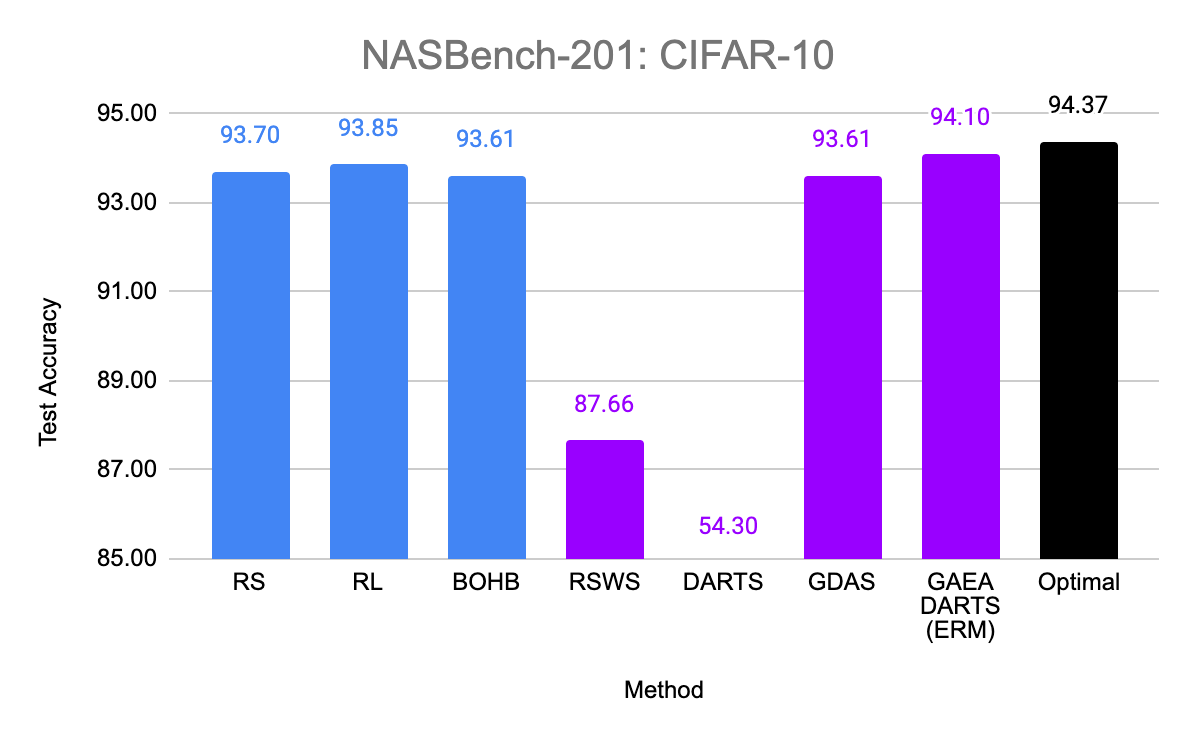
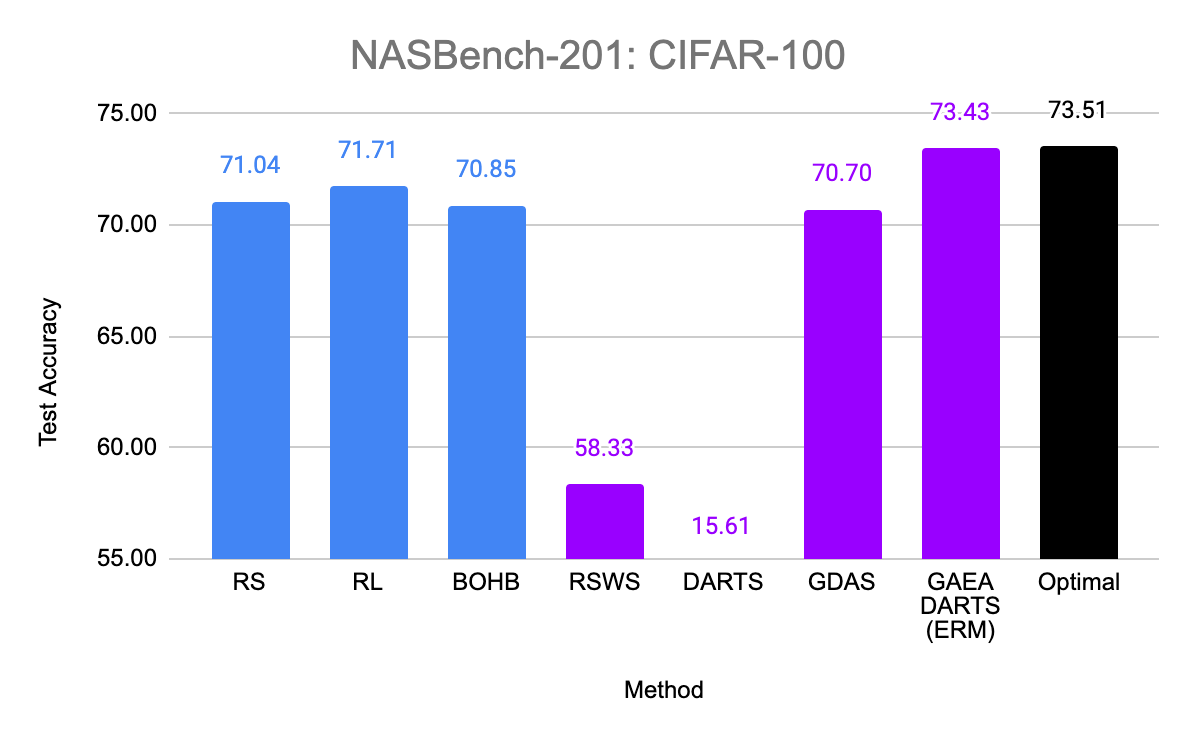
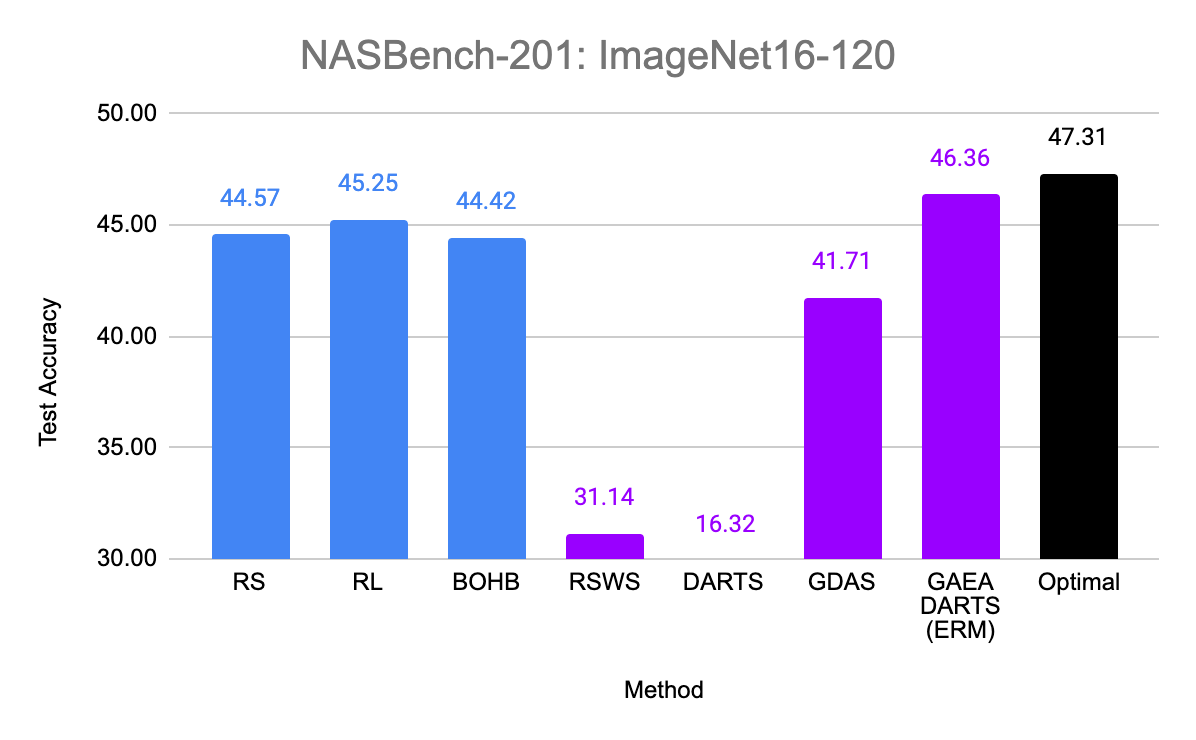
So does the sparsity and faster convergence rates of GAEA result in better performance empirically? To test this, we simply apply the two steps above to modify existing state-of-the-art NAS methods. First, we evaluate GAEA applied to DARTS on the NAS-Bench-201 search space by Dong et al. Of the methods evaluated by Dong et al., non-weight-sharing methods outperformed weight-sharing methods on all three datasets. However, GAEA DARTS applied to the single-level ERM objective achieves the best accuracy across all three datasets, reaching near oracle-optimal performance on two of them. Notably, it fixes the catastrophically poor performance of DARTS on this space and is the only weight-sharing method that beats standard hyperparameter optimization.
 |
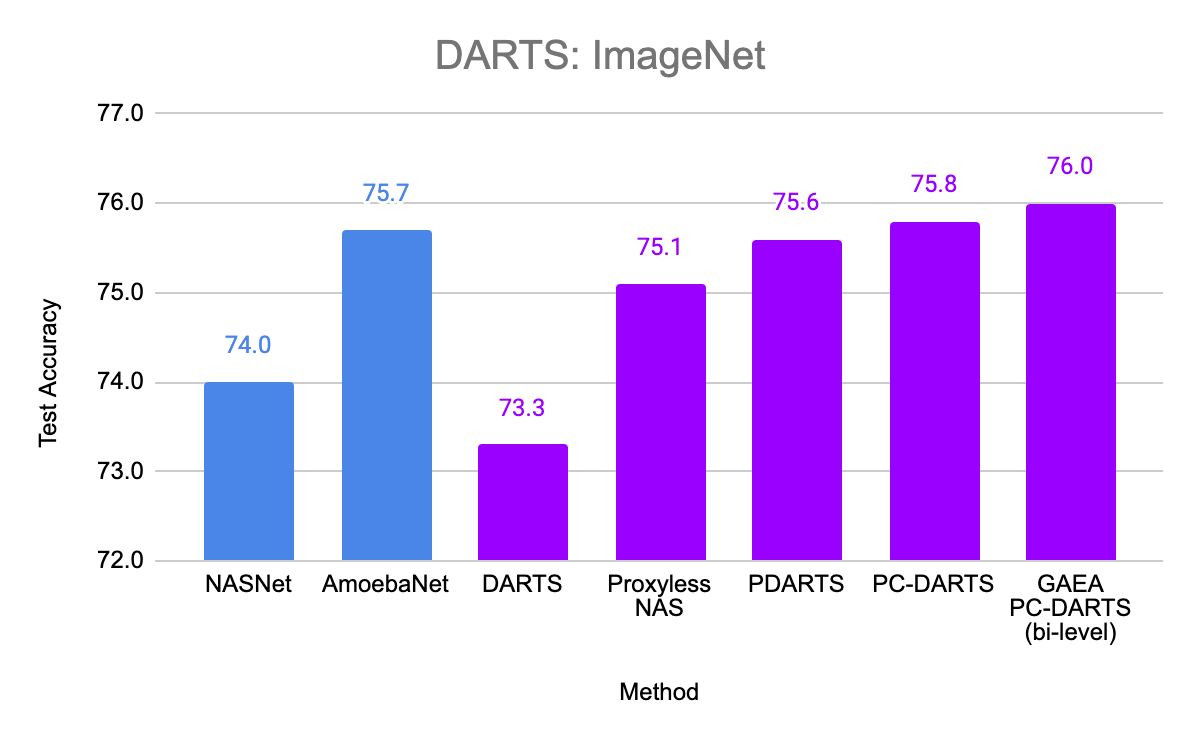 |
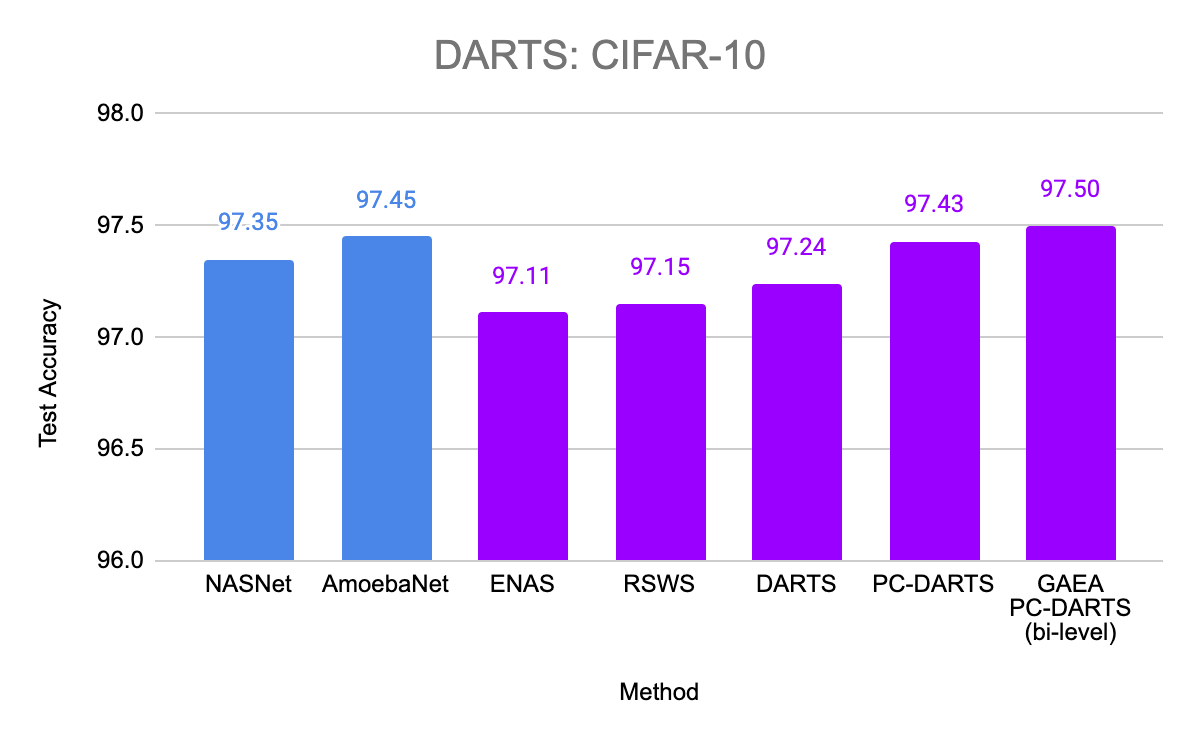
We also evaluated GAEA applied to PC-DARTS on the original DARTS CNN search space. With improved regularization for the weight-sharing optimization problem, PC-DARTS was able to recently match the performance of computationally expensive non-weight-sharing methods on CIFAR-10 and ImageNet. We are able to further boost the performance of PC-DARTS with GAEA and achieve state-of-the-art performance on this search space, demonstrating the importance of efficiently optimizing in the right geometry.
Interested in learning more?
To learn more about our results, weight-sharing, and NAS you can
- See our paper, joint with Nina Balcan and Ameet Talwalkar, for more details.
- Download our code for a full implementation of GAEA.
- Read about the original weight-sharing method, ENAS, and about the baseline weight-sharing method, RS-WS.
- Read a survey of the field (Elsken, Metzen, & Hutter, JMLR 2019).