SEP 11, 2024
How does Video Generation work?

July 17, 2024
You may have been dazzled by OpenAI’s Sora, an incredible text-to-video model that can create stunning visualizations from artist imaginings, for example:

Or a Make-A-Video:
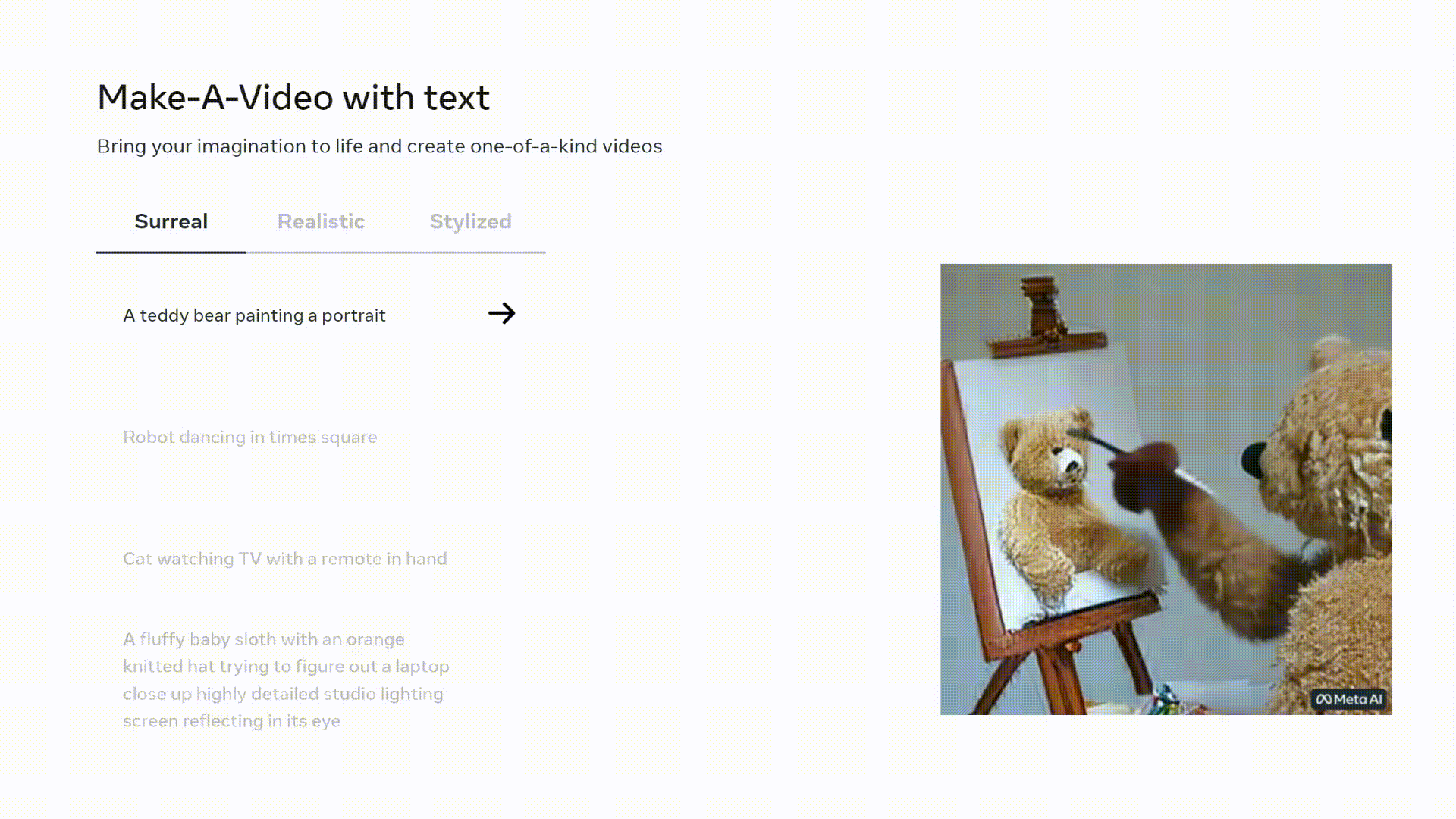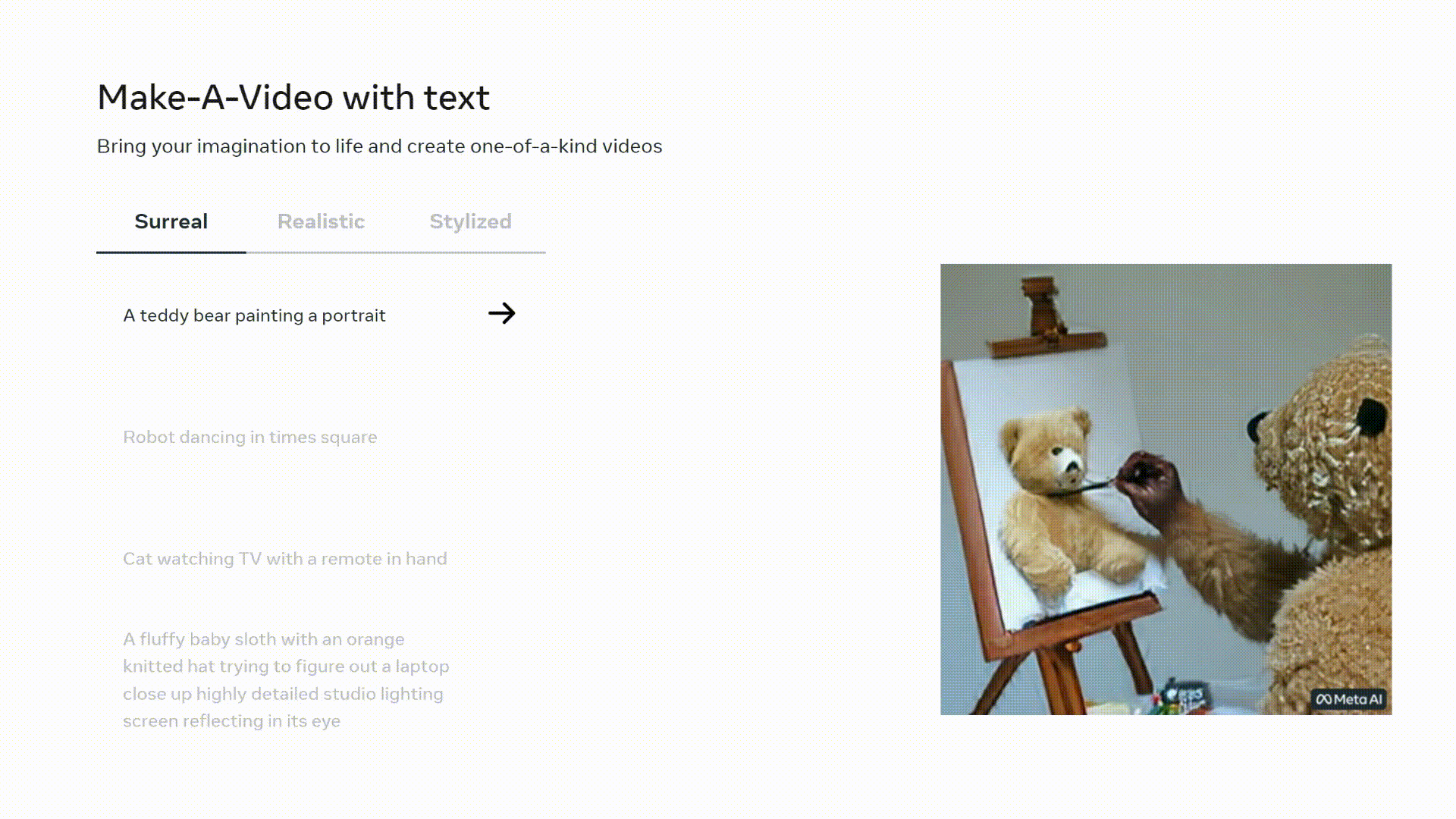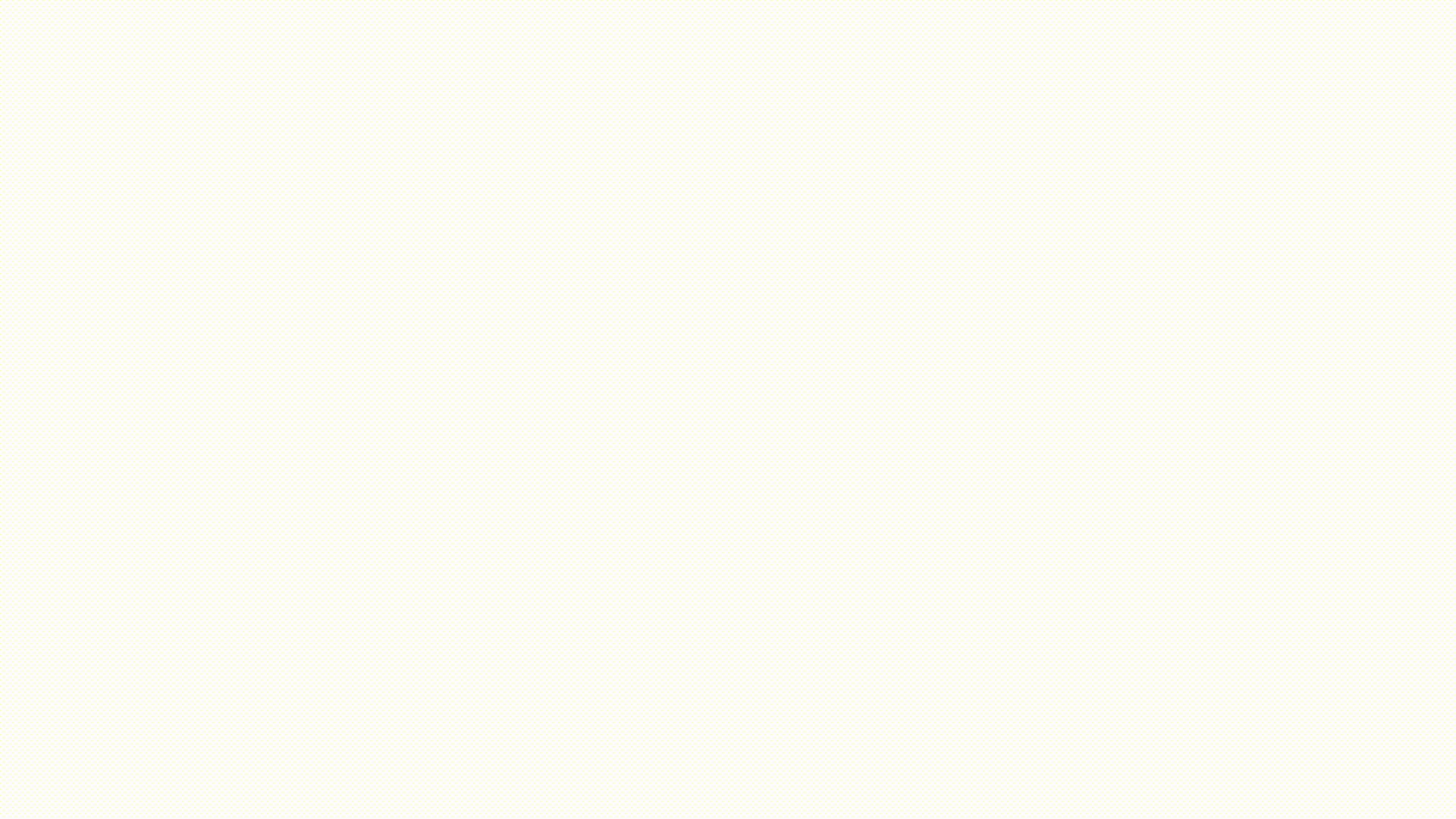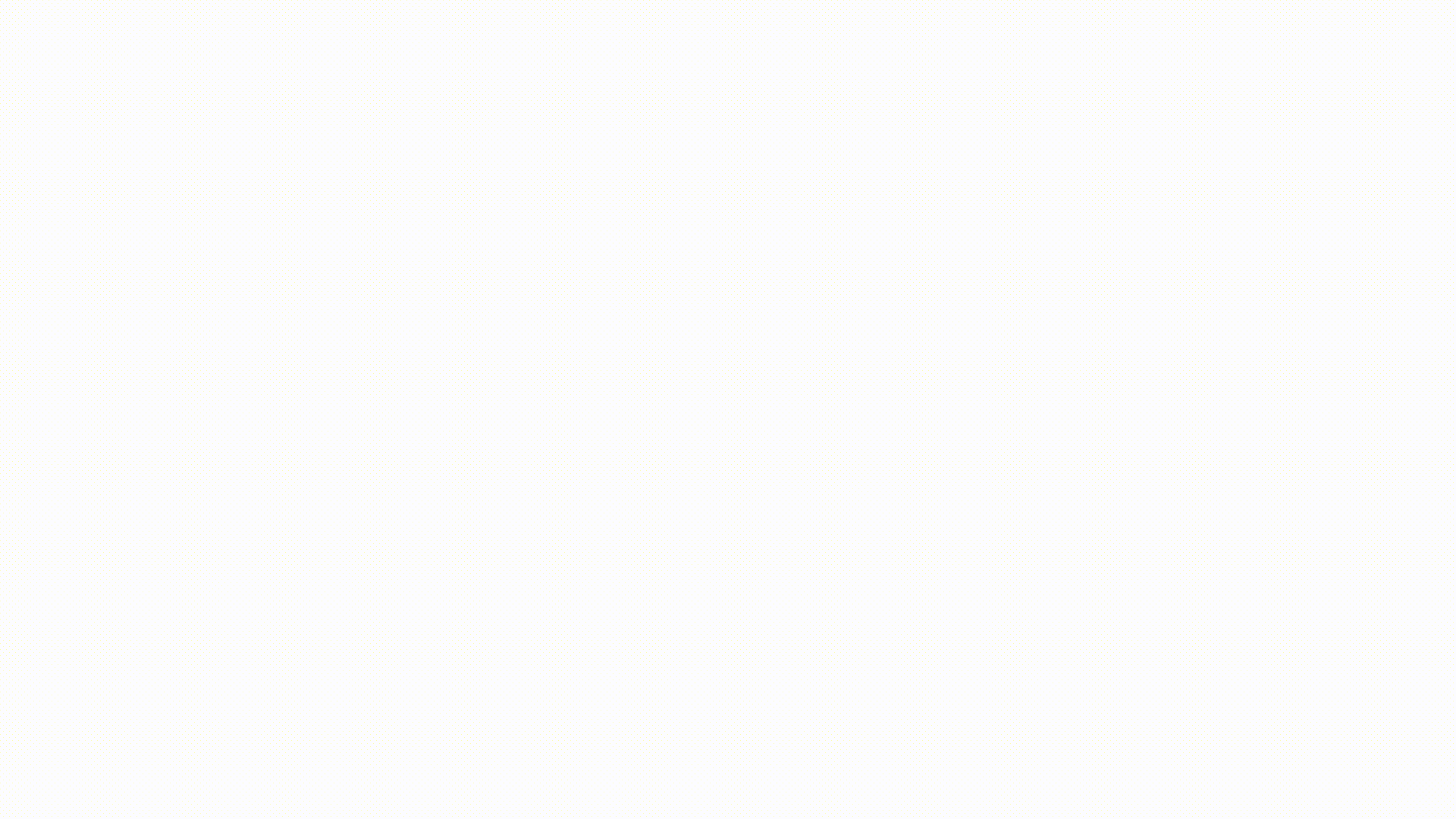
In this blog post, we’ll explore how modern image generation models are able to generate such accurate, photorealistic video. In particular, we’ll cover Sora, Make-A-Video, and Imagen Video. Let’s dive in!
Common Components
These particular state-of-the-art video generators all have a few common components:
- Video diffusion models
- Guidance through text embeddings
- Upsampling models (for both temporal and spatial upsampling)
Sora
Sora was released by OpenAI just a few months ago and is capable of generating stunning photorealistic video.
The full workflow of Sora involves two image/video resolution levels: The full-resolution scale and a compressed, latent scale.
- First, a Video Compression Network creates the compressed data from normal-resolution images and video:
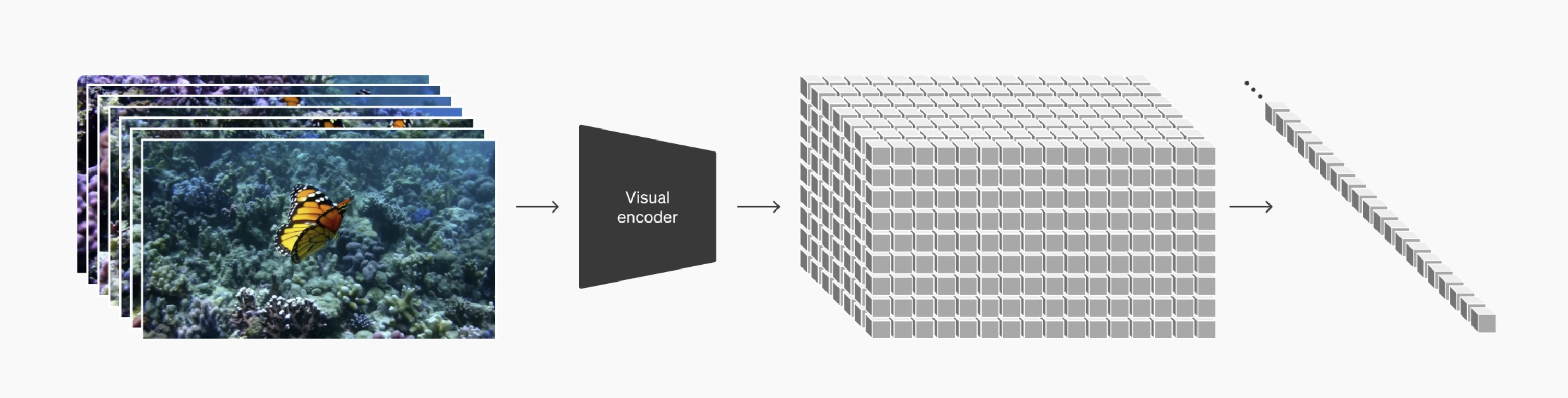
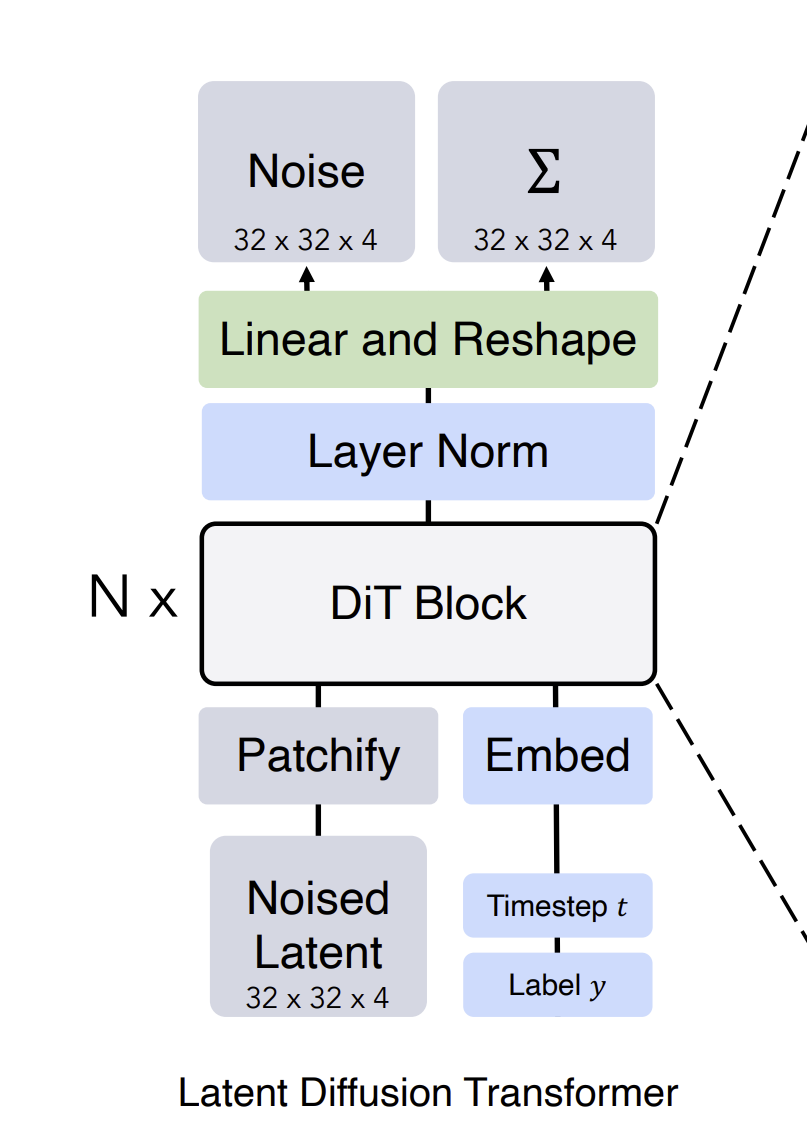
- Sora, a diffusion transformer (DiT), is trained on these latent, compressed videos. DiTs are a special type of network architecture that take in text-conditioning (e.g., user prompts) and gaussian noise, and generate a clean image guided by the text prompt. DiTs are perfect for this task because Transformer models, like the one behind ChatGPT, generate new text sequences in a feedforward fashion, while Diffusion models generate images by iteratively changing pixels in an image. Combined together, a Diffusion Transformer model is able to generate an image/video guided by a text prompt.
- Once a low-resolution video is generated by Sora in the latent space, the decoder from the Video Compression Network is used to bring it back up to full scale.
Diffusion Models
As mentioned in the previous section, SORA is a diffusion transformer. But diffusion is a general training technique that can be used with different architectures, like U-Nets. Stable Diffusion was one of the first applications of diffusion in the text-to-image domain. Read our blog post about it if you’re curious about the history of diffusers and textual inversion.
Conceptually, there are two processes involved in training a diffusion model: a forward, noising process that noises up the image, and a reverse process that denoises the image. The reverse process is what is learned, and that is what is used during inference (generation) time.
-
Forward Process: This process adds noise to the data in a series of steps. It simulates the corruption of data, where each step introduces a small amount of noise until the data is transformed into pure noise.
-
Reverse Process: This is where the model learns to predict and remove the noise added in each step of the forward process. The reverse process itself is what is learned by the model.
During inference, the model starts with a random noise vector (often Gaussian noise) and uses what it learned - the reverse process - to iteratively refine the noisy input through several steps until a final, coherent output is produced (e.g., an image or video).
What about the data?
Like many video generation models, Sora learns using text-to-video data. Usually, they’re short chunks of videos with text descriptions. Short chunks because 1) it’s difficult to meaningfully describe the video if it’s much longer than that and 2) because of computational constraints.
According to HuggingFace, WebVid was the most commonly used text-video dataset for training models that depend on these types of datasets. Currently WebVid is no longer legally allowed to provide these data since much of it was scraped from Shutterstock.
Either way, WebVid contained noisy data and inaccurate text descriptions. Huggingface mentions a few other more niche datasets that combat this data quality issue, like Howto100M and CelebVText.
But not all video generation models use text-video pairs, as we’ll see in the next section.
Make-a-Video
Make-a-Video is another photorealistic video generator that works a little differently than SORA in that:
- It does not depend on text-video pairs.
- It instead expands upon text-to-image models, utilizing the learned text-to-image mapping, and subsequently utilizes unsupervised video to learn motion.
This is beneficial because, as mentioned previously, high quality labeled video data is difficult to come by. So, Make-A-Video makes use of data types already largely available on the internet.
The architecture diagram published in the paper can be confusing:
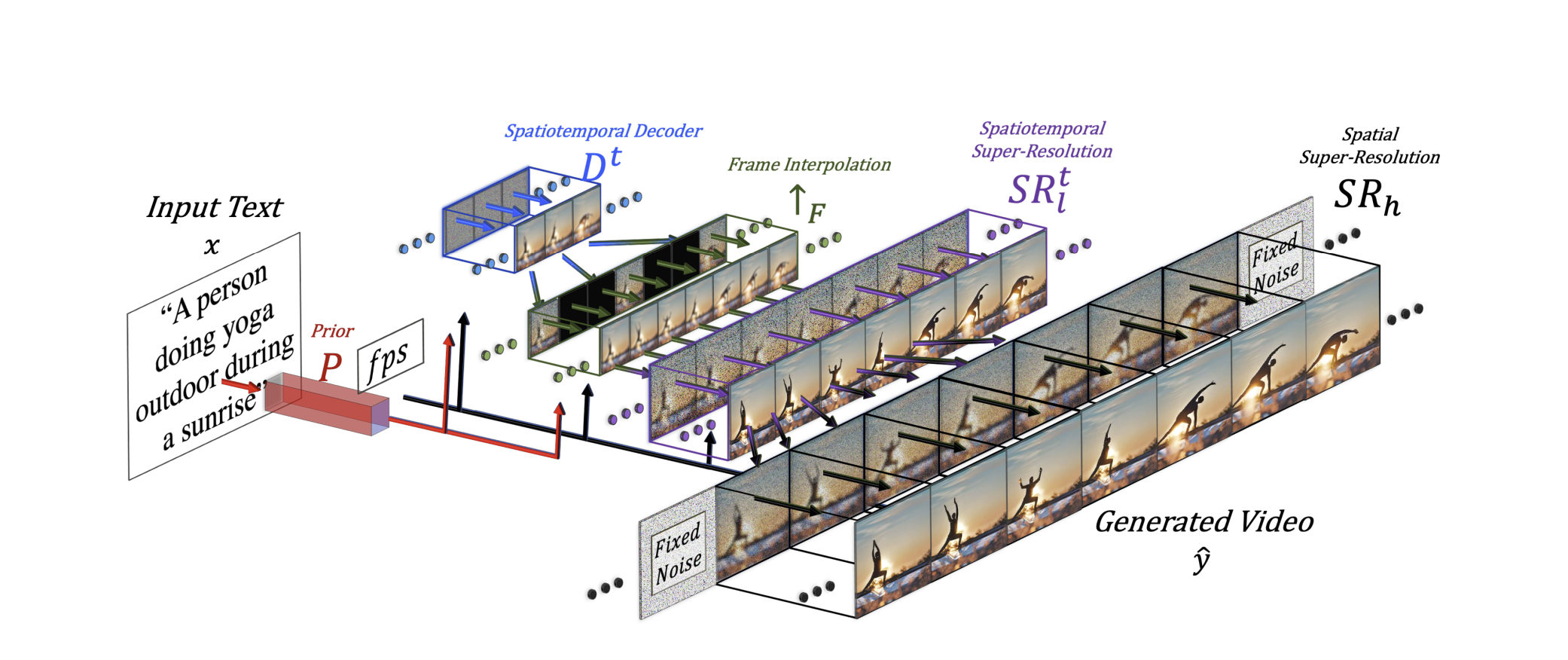
but to break it down, there are 3 main stages and several neural networks involved in training Make-A-Video:
Stage 1: Generate images from text
First, a text-to-image model is trained to generate an image based on some text input in DALL·E 2 fashion. Three models are involved here:
- A prior, which generates image embeddings from text,
- A decoder which generates an image from those image embeddings,
- And two superresolution networks (spatial and spatiotemporal) that upsample this image into higher resolution.
All of this is in service of generating an image from text, and all these models are trained on text-to-image data only. The decoder here uses CLIP image embeddings to generate the image. If you’re not familiar with how text embeddings and image embeddings work together, we covered CLIP in our blog about multimodal LLMs.
Stage 2: Learn from Unlabeled Video
After training the image generation components, they extend the Unet architectures – both convolutional and attention layers - to include temporal layers, and fine-tune them over unlabeled video data to learn movement from video.
Stage 3: Interpolate frames
Using a frame interpolation network trained on masked video frames, the generated video is expanded to hallucinate frames to make it longer.
Finally, Make-A-Video is able to generate high-quality video from text prompts due to the robust text-image generation capabilities followed by its unsupervised learning from patterns in videos.
Imagen Video
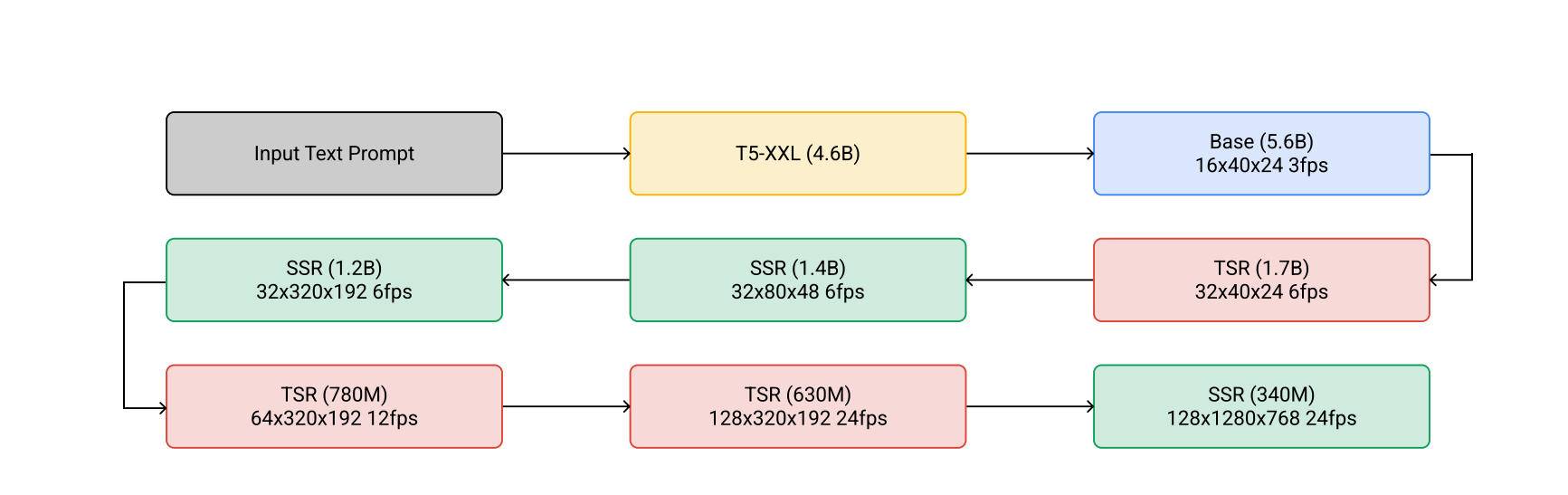
Imagen Video, based on its text-to-image counterpart, Imagen, is very similar to Make-A-Video. However, unlike Make-a-Video, it does depend on text-video data pairs. Imagen depends on 7 total neural networks. It operates in 3 stages:
-
Text input are converted to embeddings. Instead of using CLIP embeddings, Imagen uses T5-XXL to generate text embeddings.
-
A base diffusion model takes these embeddings and outputs video. This model is trained on the text-video data (or text-image data, where images are treated as a single frame video).
-
Then a frame interpolation network and a couple of superresolution networks upsample this low-res video into a higher resolution one.
And that’s it! Now you know the building blocks behind video generation models.
Interested in more AI & ML content? Stay up to date by joining our Slack Community!