The fastest and easiest way to build deep learning models.
Train Models |

Build More |
Get More Out of |

Track and Reproduce |

Tune hyperparameters
Build more accurate models faster with scalable hyperparameter search, seamlessly orchestrated by Determined. Use state-of-the-art algorithms and explore results with our hyperparameter search visualizations.
Analyze your results
Interpret your experiment results using the Determined UI and TensorBoard, and reproduce experiments with artifact tracking. Deploy your model using Determined's built-in model registry.
Share cluster resources
Easily share on-premise or cloud GPUs with your team. Determined’s cluster scheduling offers first-class support for deep learning and seamless spot instance support.

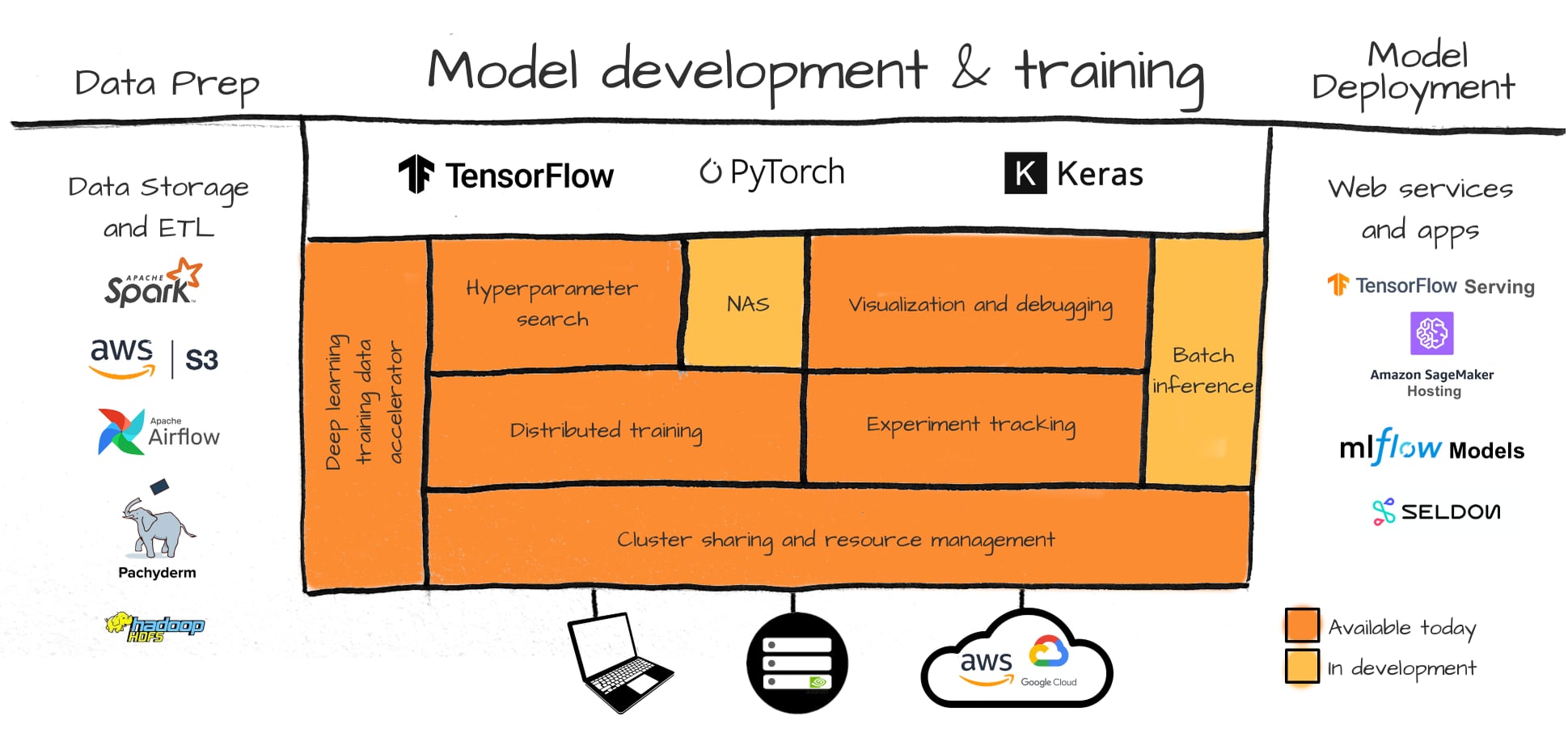
Featured Examples with Determined
Check out examples of how you can use Determined to train popular deep learning models at scale
Deep Learning in hours and minutes, not days and weeks.

Ship models faster and do more science!
Our open-source deep learning platform enables you to train models in hours and minutes, not days and weeks.

Focus on research and models
Instead of arduous tasks like manual hyperparameter tuning, re-running faulty jobs, and worrying about hardware resources.

Distributed training as it was meant to be
Our distributed training implementation outperforms the industry standard, requires no code changes, and is fully integrated with our state of the art training platform.
Share resources, experiments, and data
— and do it safely.

Real-time experiment dashboard
With built-in experiment tracking and visualization, Determined records metrics automatically, makes your ML projects reproducible, and allows your team to collaborate more easily.

Sophisticated checkpointing and resource scheduling
Your researchers will be able to build on the progress of their team and innovate in their domain, instead of fretting over errors and infrastructure.
Expert built for expert teams
We’re dedicated to the science of Deep Learning and are leaders in productionizing DL workflows, and we can’t wait to help your team thrive.
Your team, your infrastructure, your tools
— we support it all.

Serious compatibility
Determined works with the leading deep learning frameworks— PyTorch, TensorFlow, and Keras. We support a variety of data storage systems, and make it easy to export models to downstream serving systems.

Your infrastructure, your choice
Our platform integrates with your hardware, whether you’re in the cloud or on-premises.

Get the most out of your hardware
Determined enables all of your training-related workloads to run seamlessly on the same machines.
What our users have to say

Before Determined, we had to rely on group chat to ask if GPUs are free -- it was chaos! Determined makes GPU management easy, plus I love that it includes HP search and experiment tracking in a reliable and easy-to-use platform.

We've been impressed with the tools provided within Determined but what's most important to me is that we have a GPU resource management solution that allows me to continue to be a researcher instead of a system administrator.
By adopting Determined AI’s software platform, our team of deep learning engineers has been able to rapidly deliver new, advanced, Industrial IoT products to our customers. We’re delivering new AI features 10 times faster than before.
Recent Posts
APR 22, 2024
AI News #20
APR 19, 2024