SEP 11, 2024
Finetuning an LLM using HuggingFace + Determined


January 31, 2024
Finetuning an LLM can be tricky. There are a lot of details to take care of, like instruction formatting, text tokenization, model evaluation, metric logging, and distributed training. In this blog post, we’ll demonstrate how to use HuggingFace + Determined to simplify the process. Specifically, we’ll finetune the TinyLlama-1.1 model on a text-to-SQL task, but much of the code presented here can be re-used for other models and datasets.
If you’d prefer to jump into the code yourself, you can view and download the full example from GitHub.
Here’s how the rest of the post is organized:
TinyLlama and Text-to-SQL
TinyLlama
TinyLlama is a 1.1 billion parameter model that uses the same overall architecture and tokenizer as the Llama2 series of models. We’re using TinyLlama (specifically the chat model) because it’s less memory-hungry than the original Llama2 models, which come in much larger sizes (7B, 13B, and 70B).
Text-to-SQL
Text-to-SQL is the task of converting a natural language request into a SQL database query.
For example, given the structure of a table:
CREATE TABLE table_name_74 (
date VARCHAR,
tournament VARCHAR
)
and the question:
what is the date of the tournament in michalovce
we’d like the model to respond with the SQL query:
SELECT date FROM table_name_74 WHERE tournament = "michalovce"
It looks simple, but text-to-SQL can become very complicated as we increase the number of tables and the complexity of the requests.
Let’s see how the TinyLlama model performs on a simple text-to-SQL task, without any finetuning. To do this, we’ll grab an example from the Clinton/Text-to-sql-v1 dataset, which contains thousands of text-to-SQL examples.
Here’s the input (we’ll explain the <|im_start|> and <|im_end|> tags later):
<|im_start|>system
You are a helpful programmer assistant that excels at SQL.
When prompted with a task and a definition of an SQL table,
you respond with a SQL query to retrieve information from the table.
Don't explain your reasoning, only provide the SQL query.
<|im_end|>
<|im_start|>user
Task: what is the date of the tournament in michalovce
SQL table: CREATE TABLE table_name_74 (
date VARCHAR,
tournament VARCHAR
)
SQL query:<|im_end|>
<|im_start|>assistant
The correct response:
SELECT date FROM table_name_74 WHERE tournament = "michalovce"
And the model’s output:
SELECT date FROM table_name_74;
It starts off correctly, but misses the important WHERE condition. Let’s see if things improve after finetuning on the Clinton/Text-to-sql-v1 dataset.
Preparing the dataset
In this section, we’re going to look at snippets from our dataset_utils script that:
- Downloads the dataset.
- Creates subsets based on difficulty.
- Separates each subset into training/validation/testing splits.
Before we begin, we need to install some Python packages:
pip install transformers datasets evaluate trl
Now we can download the text-to-SQL dataset from HuggingFace:
import datasets
dataset = datasets.load_dataset("Clinton/Text-to-sql-v1")
Each sample in the dataset is a Python dictionary containing an input, instruction, and response. Here’s an example:
Input
The input contains the SQL table definitions:
CREATE TABLE table_name_74 (
date VARCHAR,
tournament VARCHAR
)
Instruction
The instruction contains the user’s request:
what is the date of the tournament in michalovce
Response
The response contains the SQL query that will answer the user’s request:
SELECT date FROM table_name_74 WHERE tournament = "michalovce"
Now we’d like to create subsets of this dataset, based on difficulty. We’re doing this because we want to see how the LLM’s overall accuracy varies with the complexity of the SQL tables and queries. To measure “difficulty” of a dataset sample, we’ll use the sum of the number of words in the input, instruction, and response.
First, we’ll write a function that converts the dataset to a pandas dataframe, and adds a column (total_length) containing the sum of each sample’s instruction, input, and response lengths:
def add_length_column(dataset):
df = dataset.to_pandas()
df["total_length"] = 0
for column_name in ["instruction", "input", "response"]:
num_words = df[column_name].astype(str).str.split().apply(len)
df["total_length"] += num_words
return df
Next, we’ll filter the dataframe by the total_length column to create easy, medium, and hard subsets. For this demo, we’ll use the first 10,000 samples of each subset, which we’ll specify using a number_of_samples argument:
def filter_by_total_length(df, difficulty, number_of_samples):
if difficulty == "easy":
return df[df["total_length"].between(10, 100)].iloc[:number_of_samples]
elif difficulty == "medium":
return df[df["total_length"].between(101, 200)].iloc[:number_of_samples]
elif difficulty == "hard":
return df[df["total_length"].between(201, 800)].iloc[:number_of_samples]
Given a particular subset, we’ll create training/validation/testing splits by converting the dataset back to a HuggingFace format, and using the train_test_split function. By default, we’ll split the dataset into 80% training, 10% validation, and 10% testing.
def create_and_save_datasets(
df, difficulty, train_ratio=0.8, val_ratio=0.1, test_ratio=0.1
):
seed = 123
# remove total_length column because we don't need it anymore
df = df.drop(columns=["total_length"])
dataset = datasets.Dataset.from_pandas(df, preserve_index=False)
# split into training and "the rest"
train_valtest = dataset.train_test_split(train_size=train_ratio, seed=seed)
# split "the rest" into validation and testing
val_test = train_valtest["test"].train_test_split(
test_size=test_ratio / (test_ratio + val_ratio), seed=seed
)
dataset = datasets.DatasetDict(
{
"train": train_valtest["train"],
"valid": val_test["train"],
"test": val_test["test"],
}
)
dataset_name = get_dataset_subset_name(difficulty)
dataset.save_to_disk(dataset_name)
return dataset
Now that we have code that can download and split the text-to-SQL dataset, we can start finetuning our model.
Finetuning the LLM
To finetune the LLM, we will use HuggingFace Trainer to automate the training loop, and the Determined library for resource provisioning, distributed training, and metrics visualization.
Here’s what we need to do at a high-level:
- Create the chat template
- Load, format, and tokenize the dataset.
- Create a “completions only” data collator.
- Write a model-evaluation function.
- Create the Trainer.
- Train the model.
Create the chat template
The TinyLlama-1.1B-Chat model expects text in the chatml format, which looks like this:
<|im_start|>system
Provide some context and/or instructions to the model.
<|im_end|>
<|im_start|>user
The user’s message goes here
<|im_end|>
<|im_start|>assistant
The model understands each tag to have a specific meaning:
<|im_start|>systemmarks the beginning of the system prompt, which is a high-level instruction (e.g. “be concise”).<|im_start|>usermarks the beginning of the specific request.<|im_start|>assistantmarks the beginning of the LLM’s response.<|im_end|>is the end-of-sequence token.
We can define the chatml format using a jinja template, which we will need when creating our tokenizer:
CHAT_ML_TEMPLATE = """
{% for message in messages %}
{% if message['role'] == 'user' %}
{{'<|im_start|>user\n' + message['content'].strip() + '<|im_end|>' }}
{% elif message['role'] == 'system' %}
{{'<|im_start|>system\n' + message['content'].strip() + '<|im_end|>' }}
{% elif message['role'] == 'assistant' %}
{{'<|im_start|>assistant\n' + message['content'] + '<|im_end|>' }}
{% endif %}
{% endfor %}
"""
Load, format, and tokenize the dataset
First, let’s download the pretrained TinyLlama model and tokenizer.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v0.4"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name, eos_token="<|im_end|>")
tokenizer.chat_template = CHAT_ML_TEMPLATE
The tokenizer we’ve loaded is actually Llama2’s tokenizer. That’s because TinyLlama-1.1B-Chat was trained using Llama2’s tokenizer, with a modified eos_token and chat_template. Hence, when we load the Llama2 tokenizer, we change its eos_token to "<|im_end|>", and its chat_template to the chatml template we defined above.
Now let’s load the dataset using a function from our dataset processing script:
from dataset_utils import load_or_create_dataset
subset_name = "easy"
dataset = load_or_create_dataset(subset_name)
To make the dataset understandable for our model, we need to do the following for every sample:
- Apply the chat template.
- Tokenize the text, and encode the tokens (convert them into integers).
For step 1, the tokenizer comes with a handy function called apply_chat_template. It expects a list of strings and their roles (“system”, “user”, or “assistant”). So first, we need to extract this list from each dataset sample. Let’s write a function that does this for a single sample:
def get_chat_format(element):
system_prompt = (
"You are a helpful programmer assistant that excels at SQL. "
"When prompted with a task and a definition of an SQL table, you "
"respond with a SQL query to retrieve information from the table. "
"Don't explain your reasoning, only provide the SQL query."
)
user_prompt = "Task: {instruction}\nSQL table: {input}\nSQL query: "
return [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt.format_map(element)},
{"role": "assistant", "content": element["response"]},
]
Then we can pass the output of the above function to apply_chat_template:
formatted = tokenizer.apply_chat_template(
get_chat_format(element), tokenize=False
)
Here’s what formatted looks like, using the dataset example from earlier in this post:
<|im_start|>system
You are a helpful programmer assistant that excels at SQL.
When prompted with a task and a definition of an SQL table,
you respond with a SQL query to retrieve information from the table.
Don't explain your reasoning, only provide the SQL query.
<|im_end|>
<|im_start|>user
Task: what is the date of the tournament in michalovce
SQL table: CREATE TABLE table_name_74 (
date VARCHAR,
tournament VARCHAR
)
SQL query:<|im_end|>
<|im_start|>assistant
SELECT date FROM table_name_74 WHERE tournament = "michalovce"<|im_end|>
An LLM takes lists of integers as input. Each integer corresponds to a specific grouping of characters, also known as tokens. For example, here are five tokens from the Llama2 tokenizer, and the corresponding integer representations:
▁created: 2825
wor: 13762
fill: 5589
chrom: 27433
▁nun: 11923
Thus, we have to convert our formatted dataset sample into a list of integers representing tokens. This is exactly what the tokenizer does:
outputs = tokenizer(formatted)
We want to format and tokenize every sample in the dataset, so we’ll encapsulate the above code and pass it to the dataset’s map function:
def tokenize(element):
formatted = tokenizer.apply_chat_template(
get_chat_format(element), tokenize=False
)
outputs = tokenizer(formatted)
return {
"input_ids": outputs["input_ids"],
"attention_mask": outputs["attention_mask"],
}
dataset = load_or_create_dataset(dataset_subset)
# dataset is a dictionary mapping from split names to actual datasets
for k in dataset.keys():
dataset[k] = dataset[k].map(tokenize)
Create a “completions only” data collator
When we interact with an LLM via chat, the LLM receives text from us, and iteratively outputs text, usually until it generates an end-of-sequence token like <|im_end|>. During training, the LLM also receives text (dataset samples), but its output behavior is different. Instead of iteratively generating text, it only predicts the next token for every input token. In other words, we train the LLM so that its output is exactly the same as the input text, but shifted by 1 token.
But wait! In our text-to-SQL task, the input text includes the system prompt, the user request, and SQL table definitions. Do we really want the LLM to learn to predict these parts? After all, we’re finetuning the LLM to generate an SQL query in response to all of that. The response is also known as the “completion”, thus, we want to train on completions only. To accomplish this, we’ll use the DataCollatorForCompletionOnlyLM from the trl library. Essentially, this collator changes the labels for all irrelevant tokens to -100. Why -100? Because by default, this is the value ignored by PyTorch’s CrossEntropyLoss, which is the loss function we will be using during training.
The data collator constructor expects a string or token id sequence, that separates the response from the instructions. We’ll use "<|im_start|>assistant\n" as the separator, since the SQL query response always comes after this. To be precise, we’ll pass in the token ids:
from trl import DataCollatorForCompletionOnlyLM
response_template_ids = tokenizer.encode("<|im_start|>assistant\n", add_special_tokens=False)
collator = DataCollatorForCompletionOnlyLM(
response_template_ids, tokenizer=tokenizer
)
Write a model-evaluation function
During training we’d like to occasionally see how the model is performing on the validation set. We’ll use the BLEU score and token-level accuracy to compare the model’s output tokens with the correct tokens (the inputs shifted by 1). We can write our evaluation logic in functions named compute_metrics and preprocess_logits_for_metrics, which we will pass into the HuggingFace Trainer class:
import evaluate
bleu = evaluate.load("bleu")
acc = evaluate.load("accuracy")
def preprocess_logits_for_metrics(logits, labels):
if isinstance(logits, tuple):
# Depending on the model and config, logits may contain extra tensors,
# like past_key_values, but logits always come first
logits = logits[0]
# argmax to get the token ids
return logits.argmax(dim=-1)
def compute_metrics(eval_preds):
preds, labels = eval_preds
# preds have the same shape as the labels,
# after the argmax(-1) has been calculated by preprocess_logits_for_metrics
# but we need to shift the labels
labels = labels[:, 1:]
preds = preds[:, :-1]
# -100 is a default value for ignore_index used by DataCollatorForCompletionOnlyLM
mask = labels == -100
# replace -100 with a value that the tokenizer can decode
labels[mask] = tokenizer.pad_token_id
preds[mask] = tokenizer.pad_token_id
# bleu takes in text, so we have to translate from token ids to text
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
bleu_score = bleu.compute(predictions=decoded_preds, references=decoded_labels)
# accuracy takes in lists of integers,
# and we want to evaluate only the parts that are not -100,
# hence the mask negation (~)
accuracy = acc.compute(predictions=preds[~mask], references=labels[~mask])
return {**bleu_score, **accuracy}
Create the Trainer
The HuggingFace Trainer takes in a special TrainingArguments object that holds hyperparameters like batch size, learning rate etc. To make our project easy to configure, we’ve written our hyperparameters in a yaml config file, which you can view here.
While we’re at it, let’s use Determined to log everything about our experiment, and take care of resource provisioning and distributed training. To do that, we’ll first need to install the Determined library:
pip install determined
Now in our code, we’ll do the following:
- Create a Determined distributed context, which will enable distributed training.
- Load our hyperparameters into the
TrainingArgumentsobject. - Initialize a
DetCallback, which will automatically log losses and evaluation metrics.
import determined as det
from determined.transformers import DetCallback
from transformers import TrainingArguments
info = det.get_cluster_info()
hparams = info.trial.hparams
distributed = det.core.DistributedContext.from_torch_distributed()
with det.core.init(distributed=distributed) as core_context:
training_args = TrainingArguments(**hparams["training_args"])
det_callback = DetCallback(core_context, training_args)
Finally, we create the Trainer object and register the DetCallback:
trainer = Trainer(
args=training_args,
model=model,
tokenizer=tokenizer,
data_collator=collator,
train_dataset=dataset["train"],
eval_dataset=dataset["valid"],
preprocess_logits_for_metrics=preprocess_logits_for_metrics,
compute_metrics=compute_metrics,
)
trainer.add_callback(det_callback)
Train the model
We first evaluate, so that we can see the pretrained model’s accuracy, and then train:
trainer.evaluate()
trainer.train()
That completes the training script. To run it using Determined, we use the det e create command, along with the name of our config file, which in this case is distributed.yaml:
det e create distributed.yaml .
Now we can view the losses, accuracies, and BLEU scores in the Determined Web UI:
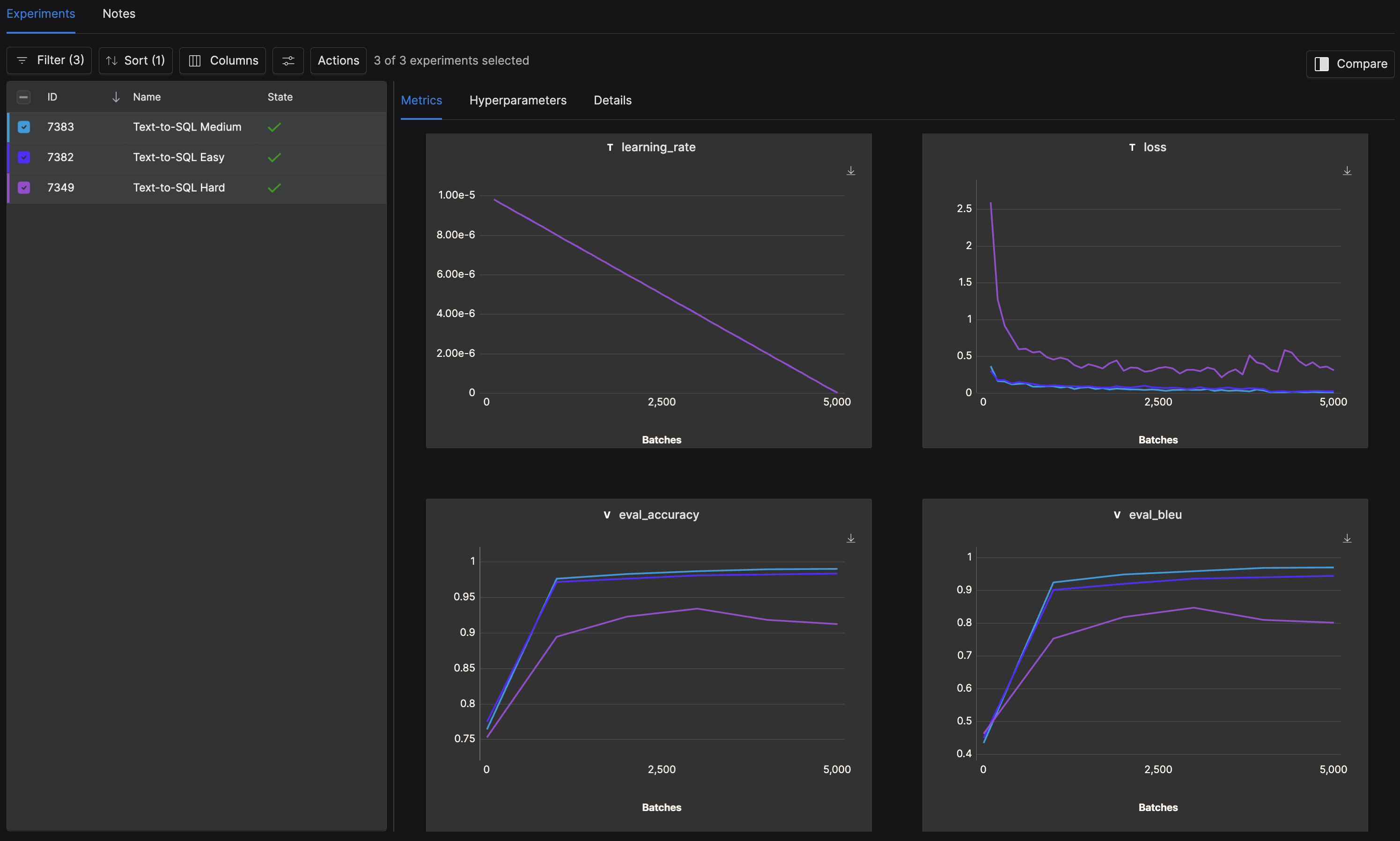
As you can see, we were able to significantly improve the BLEU score on all subsets (easy, medium, and hard).
Results
Let’s see how well the model generates SQL queries. We download the best model checkpoints using the Determined Python SDK, take an example from each difficulty subset, and pass it into the .generate() function of the model. The results are shown below.
Easy example
Input:
<|im_start|>system
You are a helpful programmer assistant that excels at SQL.
When prompted with a task and a definition of an SQL table,
you respond with a SQL query to retrieve information from the table.
Don't explain your reasoning, only provide the SQL query.
<|im_end|>
<|im_start|>user
Task: what is the date of the tournament in michalovce
SQL table: CREATE TABLE table_name_74 (
date VARCHAR,
tournament VARCHAR
)
SQL query:<|im_end|>
<|im_start|>assistant
Finetuned model response:
SELECT date FROM table_name_74 WHERE tournament = "michalovce"
Correct response:
SELECT date FROM table_name_74 WHERE tournament = "michalovce"
Medium example
Model input:
<|im_start|>system
You are a helpful programmer assistant that excels at SQL.
When prompted with a task and a definition of an SQL table,
you respond with a SQL query to retrieve information from the table.
Don't explain your reasoning, only provide the SQL query.
<|im_end|>
<|im_start|>user
Task: how many patients were admitted to the hospital before the year 2165 with an item id 50990?
SQL table: CREATE TABLE demographic (
subject_id text,
hadm_id text,
name text,
marital_status text,
age text,
dob text,
gender text,
language text,
religion text,
admission_type text,
days_stay text,
insurance text,
ethnicity text,
expire_flag text,
admission_location text,
discharge_location text,
diagnosis text,
dod text,
dob_year text,
dod_year text,
admittime text,
dischtime text,
admityear text
)
CREATE TABLE diagnoses (
subject_id text,
hadm_id text,
icd9_code text,
short_title text,
long_title text
)
CREATE TABLE lab (
subject_id text,
hadm_id text,
itemid text,
charttime text,
flag text,
value_unit text,
label text,
fluid text
)
[2 more tables]
SQL query:<|im_end|>
<|im_start|>assistant
Finetuned model response:
SELECT COUNT(DISTINCT demographic.subject_id)
FROM demographic
INNER JOIN lab
ON demographic.hadm_id = lab.hadm_id
WHERE demographic.admityear < "2165" AND lab.itemid = "50990"
Correct response:
SELECT COUNT(DISTINCT demographic.subject_id)
FROM demographic
INNER JOIN lab
ON demographic.hadm_id = lab.hadm_id
WHERE demographic.admityear < "2165" AND lab.itemid = "50990"
Hard example
Model input:
<|im_start|>system
You are a helpful programmer assistant that excels at SQL.
When prompted with a task and a definition of an SQL table,
you respond with a SQL query to retrieve information from the table.
Don't explain your reasoning, only provide the SQL query.
<|im_end|>
<|im_start|>user
Task: what is the name of the specimen test that patient 025-44495 was last given since 11/2104?
SQL table: CREATE TABLE patient (
uniquepid text,
patienthealthsystemstayid number,
patientunitstayid number,
gender text,
age text,
ethnicity text,
hospitalid number,
wardid number,
admissionheight number,
admissionweight number,
dischargeweight number,
hospitaladmittime time,
hospitaladmitsource text,
unitadmittime time,
unitdischargetime time,
hospitaldischargetime time,
hospitaldischargestatus text
)
CREATE TABLE treatment (
treatmentid number,
patientunitstayid number,
treatmentname text,
treatmenttime time
)
CREATE TABLE microlab (
microlabid number,
patientunitstayid number,
culturesite text,
organism text,
culturetakentime time
)
[7 more tables]
SQL query:<|im_end|>
<|im_start|>assistant
Finetuned model response:
SELECT microlab.culturesite
FROM microlab
WHERE microlab.patientunitstayid IN
(
SELECT patient.patientunitstayid
FROM patient
WHERE patient.patienthealthsystemstayid IN
(
SELECT patient.patienthealthsystemstayid
FROM patient
WHERE patient.uniquepid = '025-44495'
)
)
AND STRFTIME('%y-%m', microlab.culturetakentime) >= '2104-11'
ORDER BY microlab.culturetakentime DESC LIMIT 1
Correct response:
SELECT microlab.culturesite
FROM microlab
WHERE microlab.patientunitstayid IN
(
SELECT patient.patientunitstayid
FROM patient
WHERE patient.patienthealthsystemstayid IN
(
SELECT patient.patienthealthsystemstayid
FROM patient
WHERE patient.uniquepid = '025-44495'
)
)
AND STRFTIME('%y-%m', microlab.culturetakentime) >= '2104-11'
ORDER BY microlab.culturetakentime DESC LIMIT 1
Looks like it got these three examples correct!
Summary
In this blog post, we finetuned an LLM and significantly increased its accuracy on the text-to-SQL task. That said, the model’s BLEU score peaked at 84.6, so there is room for improvement. What could we improve?
Going with a bigger model is an enticing idea, but a bigger model will require more resources, right? Not necessarily! With some clever training techniques, we can make better use of our existing resources. For example, in this blog post we used data parallel processing where each GPU holds a replica of the model. This approach meant we could only train our TinyLlama model on 1 sample at a time per 80 GB A100 GPU.
So in the next blogpost, we will train the much larger Llama2-7B, and examine different parallelization strategies that enable splitting the model across multiple devices. And we’ll look at LoRA, which reduces the number of trainable parameters, effectively shrinking the model.
Want to run the code?
View and clone the full example from GitHub.
If you have any questions, feel free to start a discussion in our GitHub repo and join our Slack Community!