SEP 11, 2024
Make your deep learning cluster more efficient with resource pools

April 01, 2021
Recent progress in deep learning has come at the cost of increasingly high computational demand and energy consumption. AI21 Labs estimates training Google’s BERT language models cost up to $1.6 million per model.1 More recently, training OpenAI’s GPT-3 is estimated to have cost $12 million.2 As the cost of deep learning training increases, a crucial challenge for machine learning teams is to use their computing resources as efficiently as possible to lower costs and reduce their environmental footprint. Resource pools are a new feature in Determined 0.14.2 that gives DL engineers new tools for improving DL training efficiency. Resource pools make it easy to manage a mix of GPU instance types, as well as CPU-only instances, within a single Determined cluster without needing detailed background on AWS, GCP, or Kubernetes. ML engineers can now easily:
- Run lightweight workloads, like TensorBoards and notebooks, on CPU-only instances, reducing cost.
- Run training workloads on a mix of GPU types, enabling ML engineers to use the most effective instance type for a given training job.
- Seamlessly use a mix of spot instances and on-demand instances for different workloads.
Introducing resource pools for more efficient clusters
When training with Determined, users submit training jobs to the master node, which can dynamically spawn workers, or agents, to execute the workload. When deploying a Determined cluster, users can specify what type of agents to spawn for training. There are a variety of cloud instance types from which they can choose that provide different trade-offs of computing resources and cost, so it’s important for users to choose the right resources for specific goals to get the most value out of their money. Typically, users look for different cloud instance types depending on their job type and the maturity of a project. Initially, at the beginning of a project, a machine learning engineer is likely to want cheaper instances to perform small-scale experiments as they iterate. However, as the project matures, they are likely to want to scale up to more expensive machines as they run longer jobs, train on larger datasets, or perform large-scale hyperparameter searches. ML engineers that are training large NLP models, for instance, may even require machines with large amounts of memory throughout the lifetime of a project.
To support our users’ variable needs for different computational resources, we’re introducing the ability to manage multiple instance types within a single Determined cluster. In the past, a Determined cluster only supported spawning one agent type, specified at cluster deployment time. To use different instance types, ML Engineers had to reconfigure Determined or switch between multiple Determined clusters, while DevOps Engineers would be saddled with the burden of deploying and managing a large and disparate set of clusters.
Now, with heterogeneous instance support, users can configure a single Determined cluster to manage a variety of instance types. To support this, we are introducing the concept of a resource pool, which is a set of resources that are identical and located physically close to each other. A resource pool consists of computing resources from a single resource provider (e.g., on-premise, AWS, GCP), from a single region and a single availability zone, for a single instance type. This means you can create one resource pool with one type of machine and a second resource pool with a different type of machine, instead of needing two clusters. Below we’ll outline how to set up and use resource pools in your Determined cluster.
How to use resource pools
When configuring a Determined cluster for deployment, specify one or more resource pools in the master configuration and designate which pool should be the default for GPU and CPU tasks, respectively. Lightweight tasks that only require a CPU, such as TensorBoard, will run on the default CPU pool unless otherwise specified. Tasks that require a slot such as Experiments or GPU-notebooks will launch onto the default GPU pool unless otherwise specified. Scheduling behavior can also be configured on a per-pool basis: for example, you can use the fair-share scheduler in one pool and the priority scheduler in another. Note that updating any field in the resource-pool scheduler will override all global scheduler defaults for the pool. In the example configuration shown below, we created two resource pools on AWS, one used for CPU resources and another used for GPU resources.
resource_manager:
type: agent
scheduler:
type: fair_share
fitting_policy: best
default_cpu_resource_pool: aws-small
default_gpu_resource_pool: aws-large
resource_pools:
- pool_name: aws-small
description: Default CPU resource pool
provider:
type: aws
instance_type: t2.medium
max_instances: 4
- pool_name: aws-large
description: Default GPU resource pool
provider:
type: aws
instance_type: p3.8xlarge
max_instances: 4
Once the cluster is deployed, an ML engineer can request a workload to be run on a specific resource pool using the experiment configuration, specified at runtime. If no pool is provided, Determined will use the pool specified in either default_cpu_resource_pool or default_gpu_resource_pool. In the following example we’ve requested 8 GPUs in the aws-p3.8xlarge resource pool in our experiment’s YAML configuration file.
resources:
resource_pool: aws-p3.8xlarge
Once your experiment is deployed, you can track the availability and usage of your resource pools in the Cluster page of the Web UI. There, you’ll find visualizations to monitor the status of all GPUs in the cluster across resource pools to show whether they are running workloads, pending, or free. We also visualize the status of each resource pool independently to show each cluster’s metadata as well as how many instances are being used.
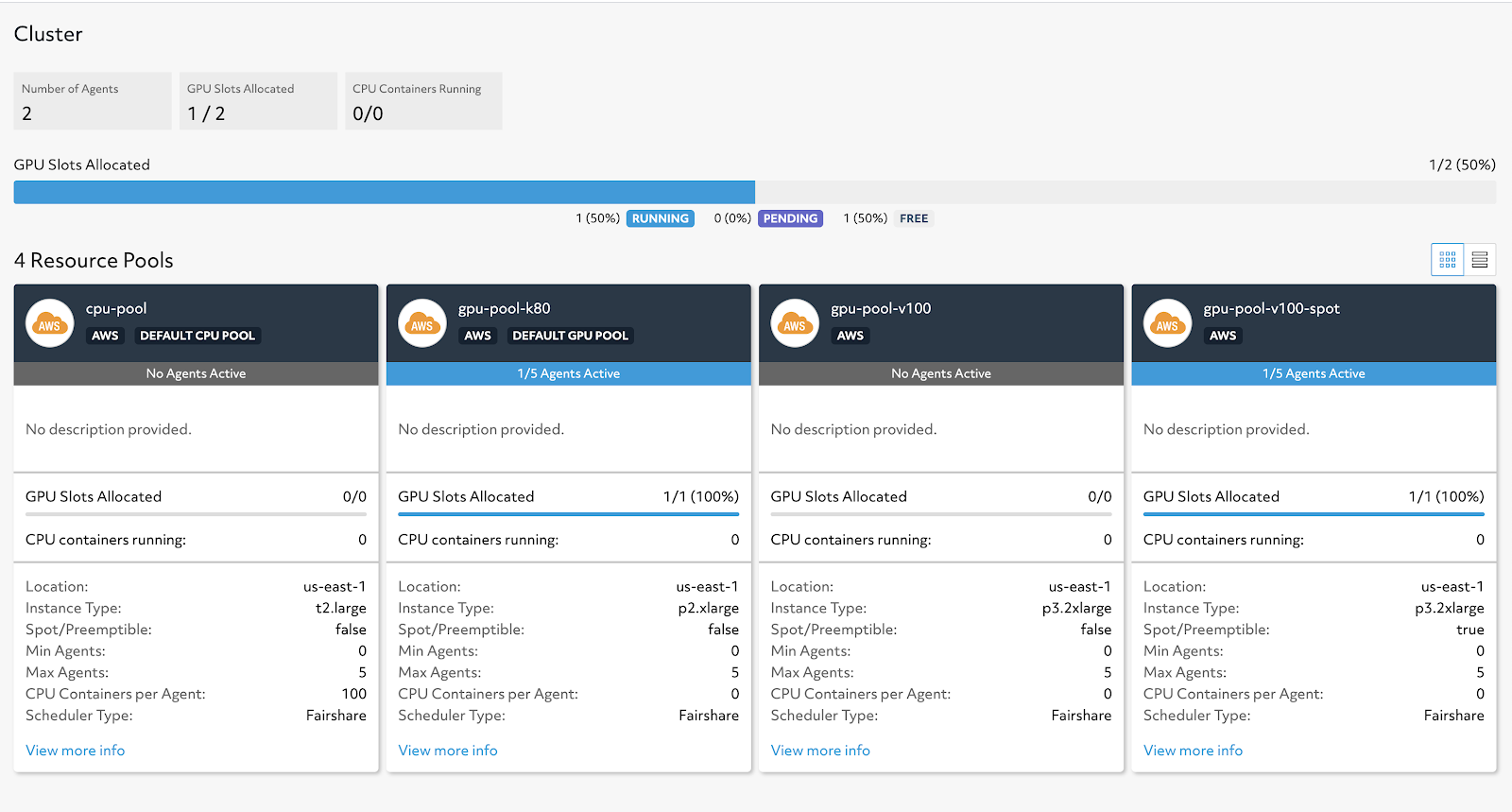
At any given time, there’s a limited number of spot instances or on-demand instances of a specific type available in an availability zone. One of the added benefits of having access to multiple resource pools in a cluster is that users can try deploying to various availability zones to secure their desired resources when running experiments. By deploying to different availability zones you can maximize the chances of getting your resource request satisfied.
Caveats and future work
Currently, Determined does not allow a cluster to have resource pools in multiple AWS/GCP regions or across multiple cloud providers. If the master is running in one region, all resource pools must also be in that region. Users are also responsible for manually selecting which pool a job should run in. In the future, we hope to address this by providing a scheduler that can automatically schedule workloads onto different resource pools based on availability. We also hope to add additional features, such as the ability to dynamically add resource pools without restarting the cluster and to fall-back to on-demand resource pools when spot instances are not available.
Learning more
For more information on resource pools, we encourage you to check out our documentation. If this is your first time getting started with Determined, check out our quick start guide or our video walkthrough of how to install Determined on AWS. If you have any questions along the way, hop on community Slack or visit our GitHub repository – we’d love to help!
-
The Cost of Training NLP Models. Sharir et al. April 2020. ↩
-
OpenAI’s Massive GPT-3 Model is Impressive, but Size Isn’t Everything. Khari Johnson. June 2020. ↩