SEP 11, 2024
Training Arbitrary Models Made Easy With Core API

June 22, 2022
Users of Determined have always faced a small but annoying barrier to entry: porting their model training scripts to use one of the Determined Trial APIs. Similar to popular libraries like PyTorch Lightning, our Trial APIs provide user-definable hooks for each step in a standard model training workflow. Our behind-the-scenes execution harness then handles the messy details of providing scalable, distributed, preemptible training with full access to features like hyperparameter search and checkpoint management.
Over time, we’ve realized that ML teams often have extensive script libraries and custom execution harnesses of their own, which make this porting process non-trivial. To address this, we designed Core API: an API with fewer built-in assumptions, which can be plugged into existing code with minimal fuss. We’ve released it as part of Determined 0.18.0.
In this post, we’ll walk through converting an existing training script to use the full set of Core API features. We’ll proceed in steps to illustrate how Core API enables incremental adoption of features. And - instead of working with a toy example - we’ll use the training script from Ross Wightman’s popular timm library for image models.
To follow along, all you’ll need is the Determined CLI and a Determined cluster with at least two GPUs. Check out the Getting Started section of our Docs for details on setting up Determined. Scripts and configuration files for this post can be downloaded on our GitHub repo here.

Why Core API?
Until now, Determined has offered scheduling, distributed training, metrics reporting, checkpoint tracking, and hyperparameter search to PyTorch and Keras models. Users only had to implement the PyTorchTrial or TFKerasTrial interface to integrate with the platform.
Still, we know many ML teams have extensive script libraries and custom training loops of their own. Ideally, they would like to access the benefits of the Determined platform without refactoring their code as a Trial class. By using Determined’s Core API, released in Determined 0.18.0, users can fully integrate arbitrary models and training loops into the Determined platform. With minimal fuss, you can now augment any training loop with all of the features provided by the Trial APIs.
In this blog post, we’ll review the step-by-step process on how to get started with Core API.
Step 0: Running the Script
To start off, we’ll show how to run the script on a single GPU with no modifications. We copied the script unchanged from Ross Wightman’s training script to step0-run.py. Changes in 0.18.0 allow us to run arbitrary executables in a Determined experiment by setting them as our entrypoint, so we can use the following configuration to train on CIFAR10:
entrypoint: python step0-run.py --dataset=torch/cifar10 --dataset-download data --input-size 3 32 32 --epochs 5
max_restarts: 0
searcher:
name: single
max_length: 1
metric: val_loss
We’ll talk more about searcher in Step 4, but for now we can safely ignore max_length and metric. Setting the searcher to single means this experiment will only create one trial.
We also need to make sure timm gets installed in each task container. We’ll use the following startup-hook.sh file, which will run in each container before running our entrypoint:
pip install timm
We can now launch training using det experiment create step0-run.yaml . and monitor training logs through the Web UI.
Step 1: Distributed Training
The timm training script uses PyTorch Distributed to do distributed data-parallel training, with the essential bit of configuration being this call:
torch.distributed.init_process_group(backend="nccl", init_method="env://")
init_process_group will then pull information from environment variables about how to connect with other processes and coordinate distributed training.
When we set slots_per_trial to something bigger than 1 in our experiment configuration, the Determined master takes care of starting up multiple copies of our entry point in containers distributed appropriately across our cluster – we just need to set those environment variables correctly in each container. In 0.18.0, we’ve provided a launch script that wraps an entry point and handles this environment setup, along with similar scripts for DeepSpeed and Horovod. Our main step toward distributed training is to modify our entrypoint with the appropriate launch script. While we’re at it, we’ll bump slots_per_trial to 2 to tell the Determined master we want to use two GPUs:
name: core-api-timm-step1
entrypoint: >-
python -m determined.launch.torch_distributed
python step1-distributed.py --dataset=torch/cifar10 --dataset-download data --input-size 3 32 32 --epochs 5
max_restarts: 0
resources:
slots_per_trial: 2
searcher:
name: single
max_length: 1
metric: val_loss
We also need a small edit during initialization in main to set args.local_rank appropriately instead of getting it from the command line:
if "LOCAL_RANK" in os.environ:
args.local_rank = int(os.environ["LOCAL_RANK"])
else:
args.local_rank = 0
And that’s it! If we launch this updated configuration, we can now confirm in the logs that we’re training across two GPUs:
[rank=0] || Training in distributed mode with multiple processes, 1 GPU per process. Process 0, total 2.
[rank=1] || Training in distributed mode with multiple processes, 1 GPU per process. Process 1, total 2.
If our cluster has more GPUs, we can make use of them by setting slots_per_trial to a higher value. This works even if the GPUs are distributed across multiple nodes. For more on distributed training in Determined, check out our docs.
Step 2: Collecting Metrics
Currently, the experiment overview page is blank:
Let’s report our metrics to the Determined master, so we can see some nice graphs instead!
First, we need to import Determined:
import determined as det
Next, we’ll initialize a Core API context and pass it into our main function:
distributed = det.core.DistributedContext.from_torch_distributed()
with det.core.init(distributed=distributed) as core_context:
main(core_context)
The Distributed Context we create here provides simple synchronization primitives used to coordinate Core API functionality across workers. If you’re running with one of the launch scripts we mentioned in Step 1, you can use the associated from_* helper function to create one from the corresponding environment variables – otherwise, you can initialize one manually.
Reporting a dictionary of metrics is now a single API call:
The original script already takes care of aggregating metrics across workers.
train_metrics = train_one_epoch(...)
Metrics can only be reported on rank 0, to avoid duplicate reports.
if args.rank == 0:
core_context.train.report_training_metrics(steps_completed=latest_batch, metrics=train_metrics)
And similarly for validation metrics:
eval_metrics = validate(
model, loader_eval, validate_loss_fn, args, amp_autocast=amp_autocast
)
...
if args.rank == 0:
# Prefix metrics with val_ to distinguish from training metrics.
core_context.train.report_validation_metrics(
steps_completed=latest_batch,
metrics={"val_" + k: v for k, v in eval_metrics.items()},
)
If we rerun our experiment and check the overview page, we can now see our metrics nicely presented:
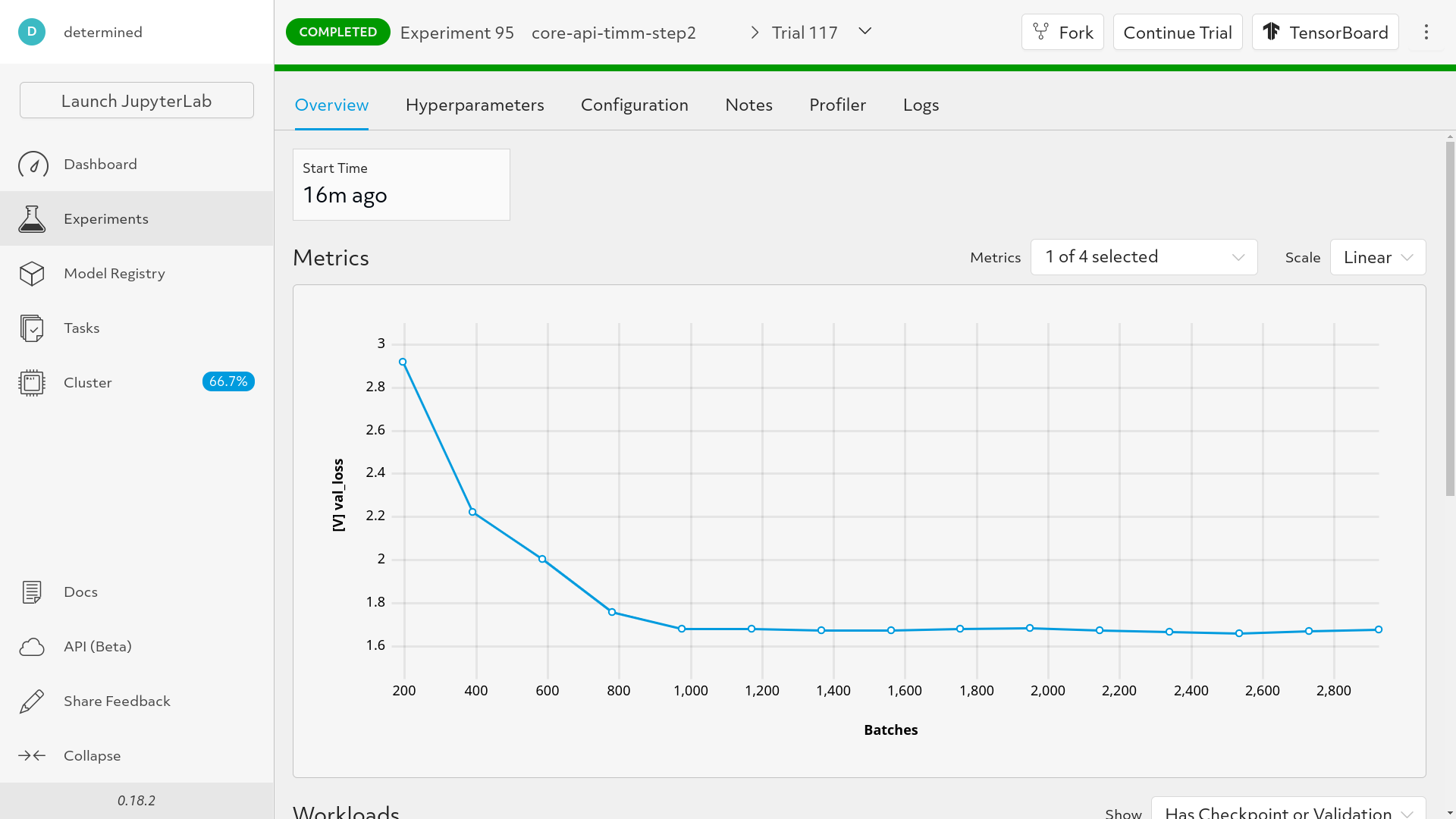
Step 3: Checkpointing
Determined supports pause/resume and preemption of training jobs via checkpoints. Unfortunately, the timm training script already has its own built-in checkpointing system. Rather than fully replace it, we’ll instead see how we can gracefully layer Determined checkpointing on top of it. In a real use case, this would avoid breaking any integrations that rely on the existing functionality.
First, we’ll pull some metadata from get_cluster_info():
info = det.get_cluster_info()
If running in local mode, cluster info will be None.
if info is not None:
latest_checkpoint = info.latest_checkpoint
trial_id = info.trial.trial_id
else:
latest_checkpoint = None
trial_id = -1
To save checkpoints, we’ll hook into the timm CheckpointSaver class with our own derived version:
class DeterminedCheckpointSaver(CheckpointSaver):
def __init__(self, trial_id, epoch_length, *args, **kwargs):
self.trial_id = trial_id
self.epoch_length = epoch_length
super().__init__(*args, **kwargs)
def _save(self, save_path, epoch, metric=None):
super()._save(save_path, epoch, metric)
checkpoint_metadata = {
"steps_completed": self.epoch_length * (epoch + 1),
"trial_id": self.trial_id,
}
with core_context.checkpoint.store_path(checkpoint_metadata) as (path, _):
shutil.copy2(save_path, path.joinpath("data"))
The essential Core API call here is core_context.checkpoint.store_path, which returns a context manager that:
- On entry, finds or creates a directory for us to write checkpoint files to, returning the path and a unique checkpoint ID.
- On exit, uploads the files to checkpoint storage (if necessary) and notifies the master.
After running the parent logic to save a checkpoint to save_path, we just shutil.copy2 the full contents of save_path to the Determined checkpoint directory without needing to know anything specific about the timm checkpoint format.
Now we just need to substitute DeterminedCheckpointSaver in for the original:
saver = DeterminedCheckpointSaver(...)
And we can now see that checkpoints are being saved:
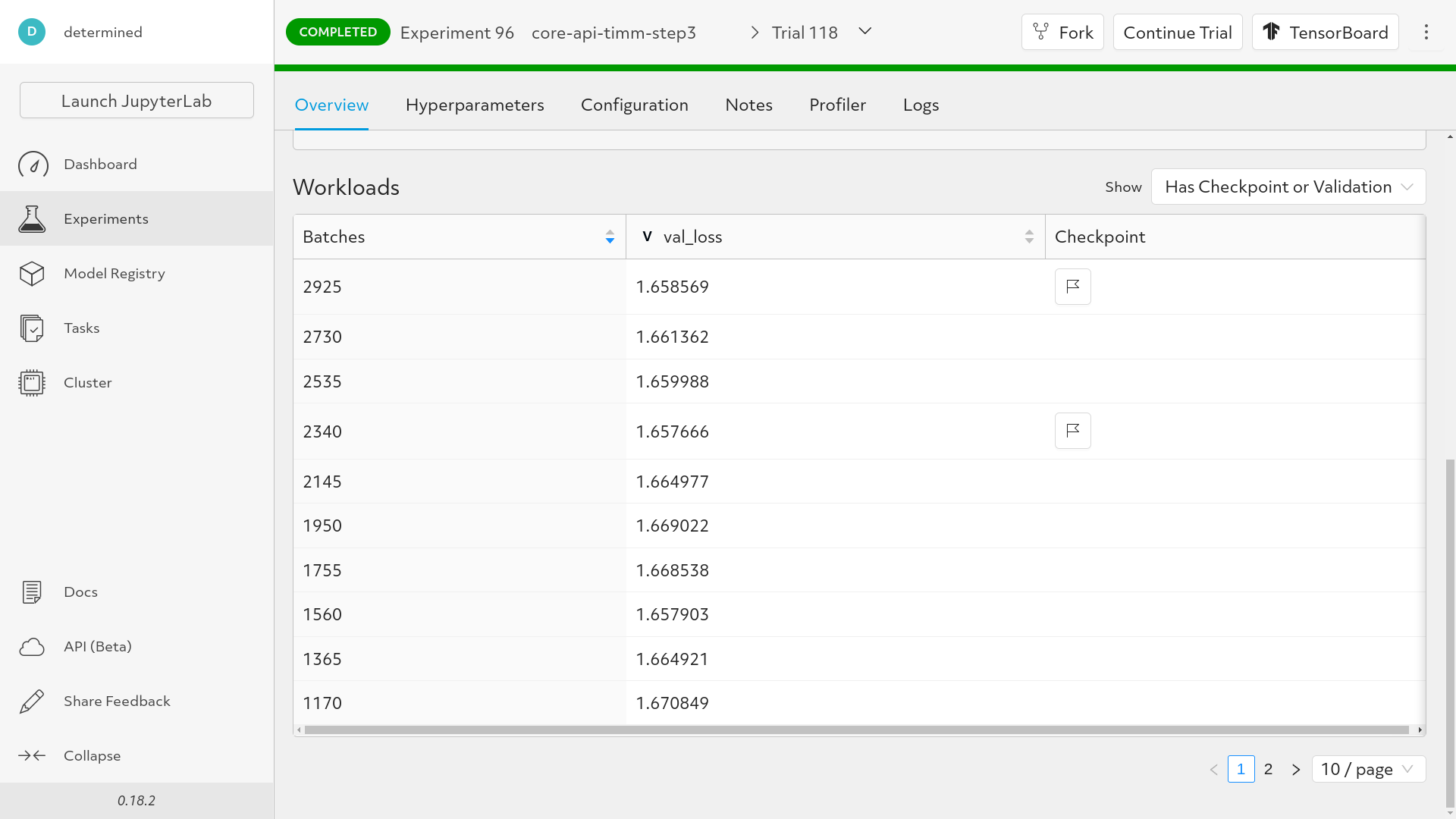
Restoring from a checkpoint is only slightly more complicated:
if latest_checkpoint is not None:
restore_path_context = core_context.checkpoint.restore_path(latest_checkpoint)
else:
restore_path_context = contextlib.nullcontext()
with restore_path_context as restore_path:
if restore_path is not None:
checkpoint_path = restore_path.joinpath("data")
else:
checkpoint_path = args.resume
if checkpoint_path:
resume_epoch = resume_checkpoint(...)
if latest_checkpoint is not None:
metadata = core_context.checkpoint.get_metadata(latest_checkpoint)
prev_trial_id = metadata["trial_id"]
if trial_id != prev_trial_id:
resume_epoch = 0
We’ll break this down piece by piece. First:
if latest_checkpoint is not None:
restore_path_context = core_context.checkpoint.restore_path(latest_checkpoint)
else:
restore_path_context = contextlib.nullcontext()
with restore_path_context as restore_path:
The centerpiece is core_context.checkpoint.restore_path, which returns another context manager. This one:
- On entry, downloads the Determined checkpoint files if necessary and returns a path to the directory containing them. A separate download won’t be necessary if checkpoints are stored in a shared filesystem.
- On exit, cleans up the files if they were downloaded.
Because the checkpoint files are only guaranteed to exist inside the with block, we manage the slightly awkward control flow by using nullcontext as a stand in when there’s no checkpoint to resume from.
Next:
if restore_path is not None:
checkpoint_path = restore_path.joinpath("data")
else:
checkpoint_path = args.resume
We continue to support the --resume script argument, but only if there’s no Determined checkpoint to continue from. Depending on your use case, you might want to flip which one takes priority.
And last:
if checkpoint_path:
resume_epoch = resume_checkpoint(...)
if latest_checkpoint is not None:
metadata = core_context.checkpoint.get_metadata(latest_checkpoint)
prev_trial_id = metadata["trial_id"]
if trial_id != prev_trial_id:
resume_epoch = 0
This addresses the two ways we might restore a Determined checkpoint:
-
Continue an existing trial, resuming at the epoch where we left off. This corresponds to the Pause/Resume button in the Web UI.
-
Start a new trial, using the checkpoint weights for initialization but starting training from epoch 0. This corresponds to the Continue Trial button in the Web UI.
As a finishing touch, you might’ve noticed that pausing our experiments in the Web UI doesn’t actually pause them! That’s because pausing an experiment (as opposed to killing one) requires our script to voluntarily shut down. For instance, we may want our script to hold off on pausing until we can finish saving a checkpoint. To correctly support pausing and other forms of preemption such as scheduler prioritization, we need to add the following after each epoch:
if core_context.preempt.should_preempt():
# Terminate the process by returning from main.
return
Step 4: Hyperparameter Tuning
To make use of Determined’s Hyperparameter Tuning functionality, we need to define our hyperparameter search space in the hyperparameters section of our experiment configuration. For demonstration, we’ll perform a five-point grid search for learning rate on a logarithmic scale from 0.01 to 0.1:
name: core-api-timm-step4
entrypoint: >-
python -m determined.launch.torch_distributed
python step4-hyperparameters.py --dataset=torch/cifar10 --dataset-download data --input-size 3 32 32 --epochs 5
max_restarts: 0
hyperparameters:
lr:
type: log
base: 10
minval: -2
maxval: -1
count: 5
resources:
slots_per_trial: 2
searcher:
name: grid
max_length: 5
metric: val_loss
Notice that we’ve also set searcher.name to grid and searcher.max_length to 5 to indicate that we’d like to run each trial for at most five epochs – more on that momentarily.
The timm training script accepts hyperparameters and other configurations through the command line using the Python ArgumentParser function. We can inject our hyperparameters into this process in the namespace argument to parse_args as follows:
def _parse_args(namespace=None):
...
args = parser.parse_args(remaining, namespace=namespace)
...
return args, args_text
def main(core_context):
info = det.get_cluster_info()
...
hparams = argparse.Namespace(**info.trial.hparams)
args, args_text = _parse_args(hparams)
_logger.info(f"Arguments and hyperparameters: {args_text}")
...
This results in command line parameters taking priority over experiment configuration hyperparameters. We can now see that we’re performing a grid search:
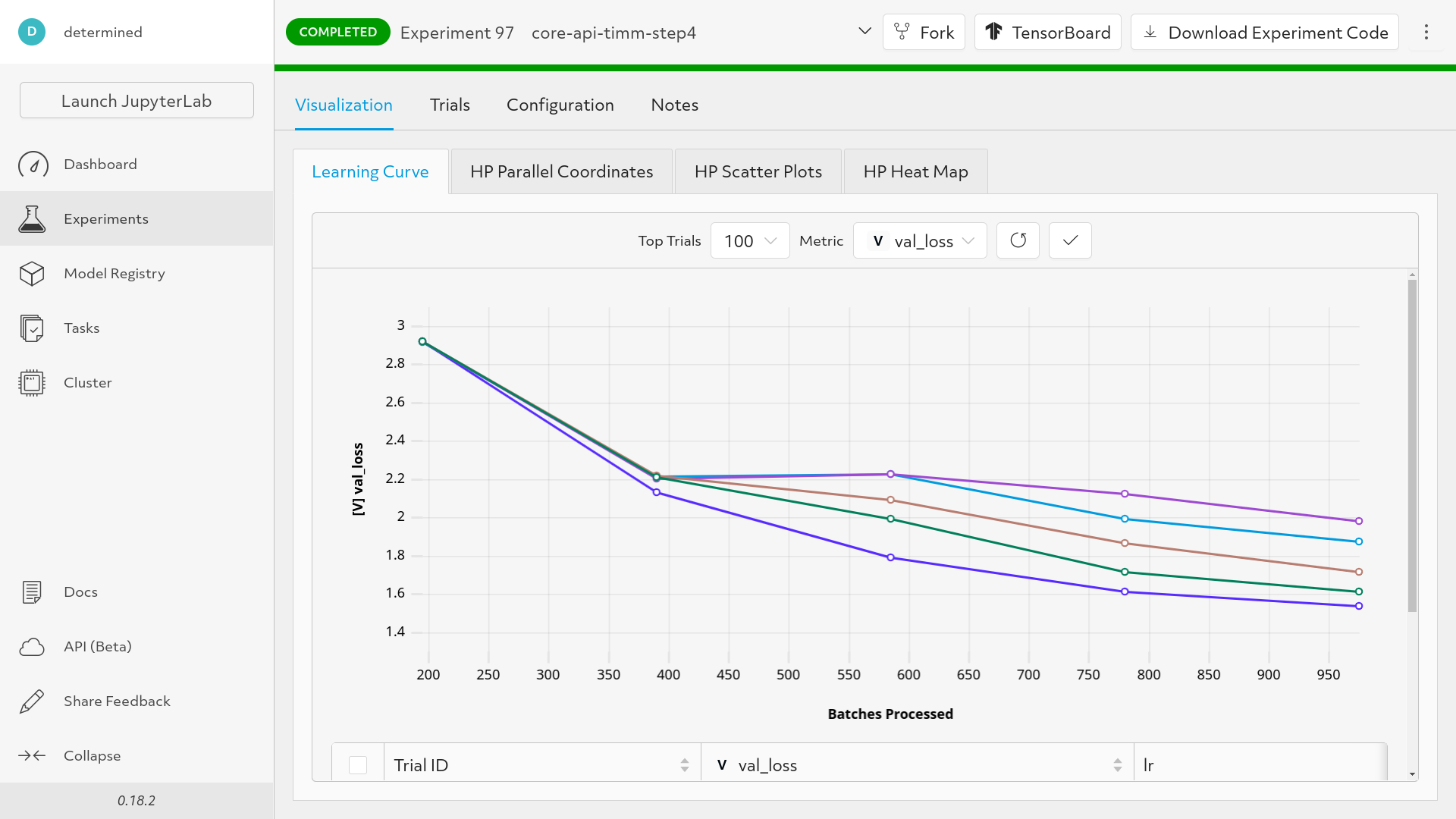
Back to searcher.max_length. Right now, we’re specifying training length through the --epochs argument. This doesn’t allow us to correctly make use of hyperparameter search algorithms like Adaptive Asha which dynamically adjust training length. If that’s fine for your use case, you can stop here.
If we instead want to respect the searcher opinion on how long we should train for, we can do the following:
next_epoch = start_epoch
for op in core_context.searcher.operations():
for epoch in range(next_epoch, op.length):
... # train for one epoch
if args.rank == 0:
op.report_progress(epoch)
...
next_epoch = op.length
if args.rank == 0:
op.report_completed(best_metric)
Here, op.length specifies the epoch we should train up to.
Conclusion
That’s it! Throughout this post, we’ve shown how to port an existing training script using the Determined Core API, and how to perform basic deep learning model training functions like metrics collection, checkpointing, hyperparameter tuning, and distributed training.
Not all machine learning workflows are created equally, so we hope that Core API eases the model porting process. If you’re just getting started with Determined, refer to our Documentation to get started and visit our GitHub page. For support and to learn more about Determined, please join our Slack Community – we’d love to hear from you!