SEP 11, 2024
AI News #19

April 15, 2024
Efficient Infinite Context Transformers with Infini-attention
- An infinite-context-window transformer that uses “compressive memory”, which is a set of parameters that store a compressed version of old context.
- Paper
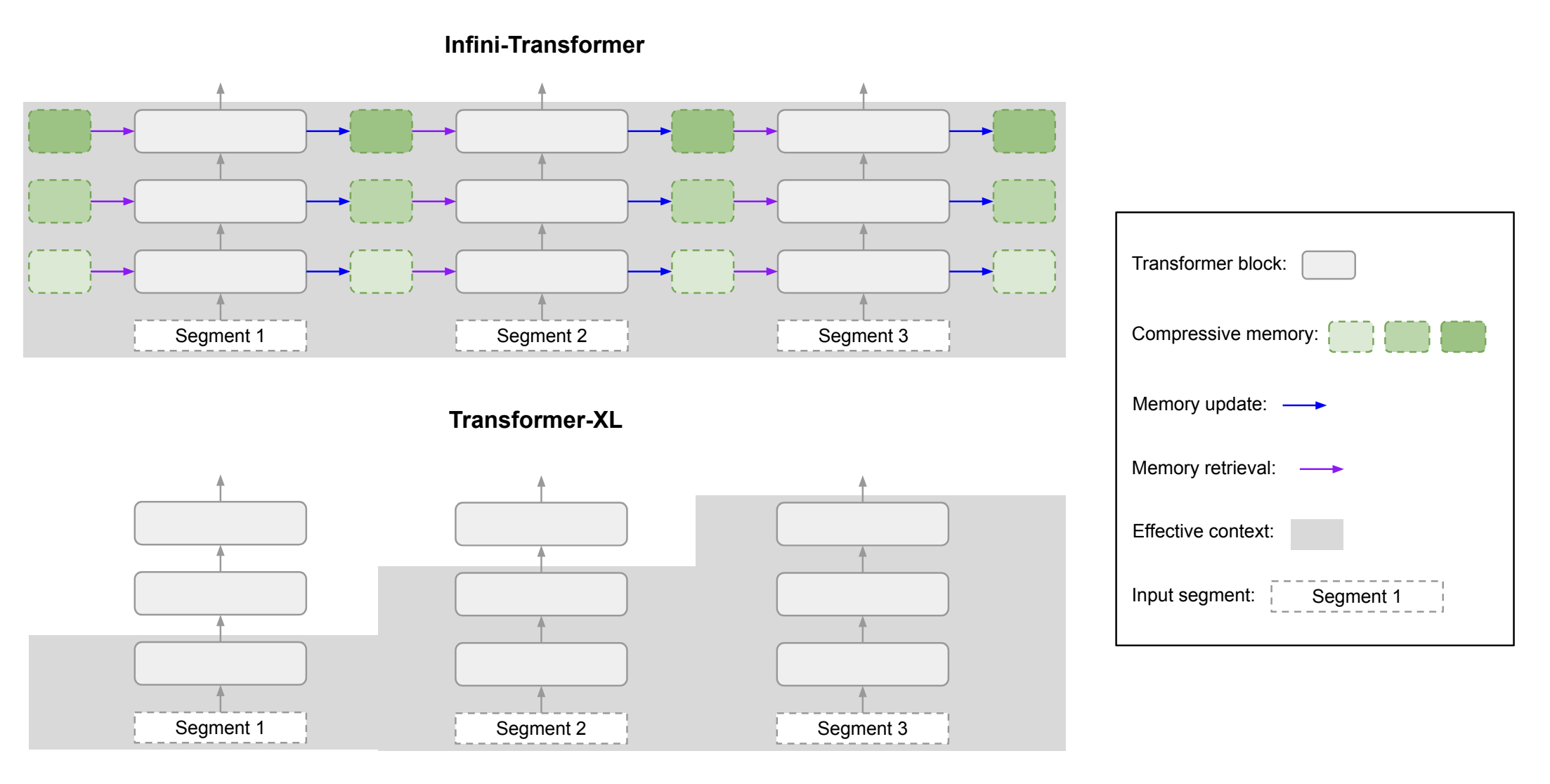
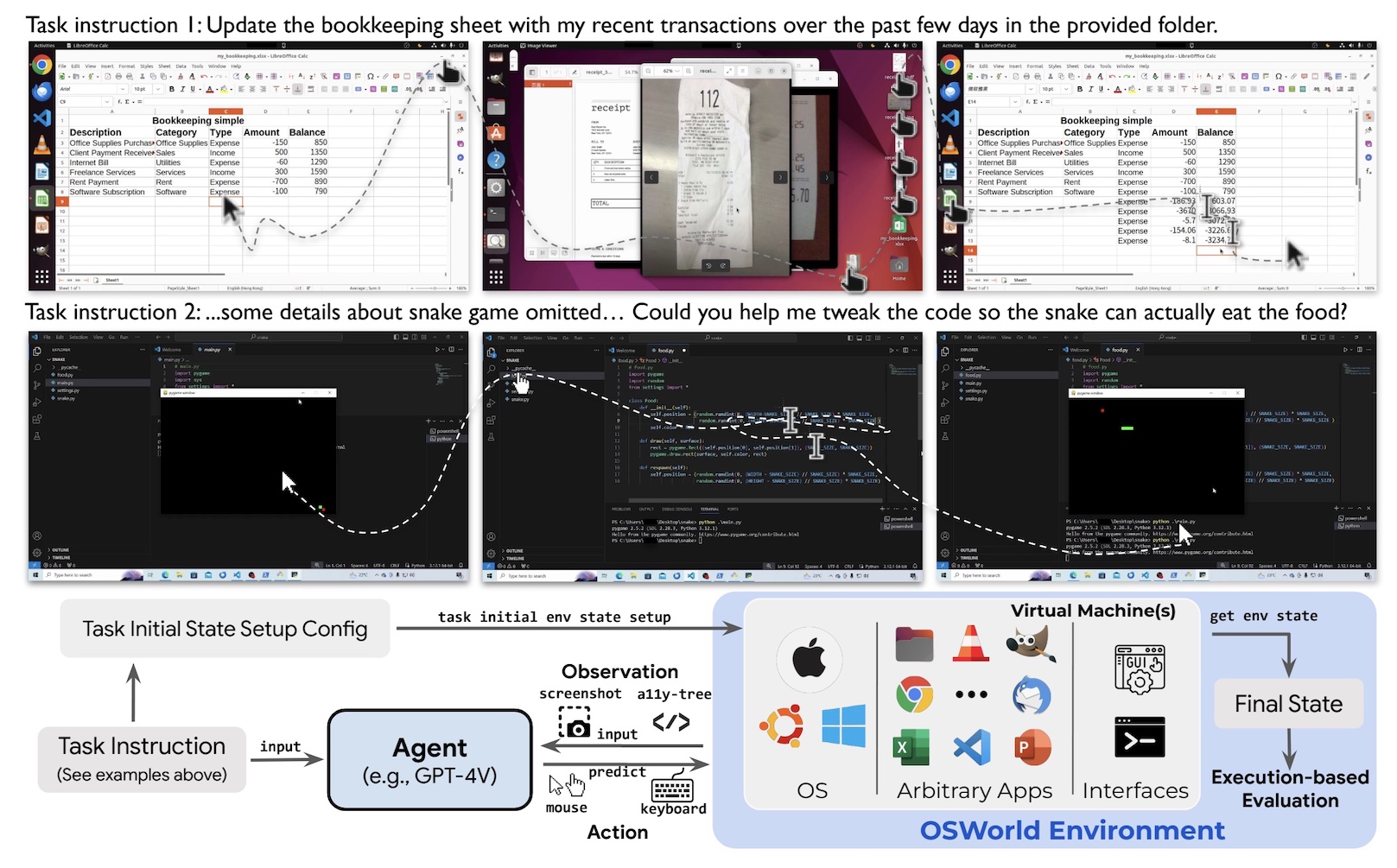
OSWorld
- An environment to test the ability of multimodal agents to perform complex tasks in operating systems like Ubuntu, MacOS, and Windows.
- Project page
- Paper
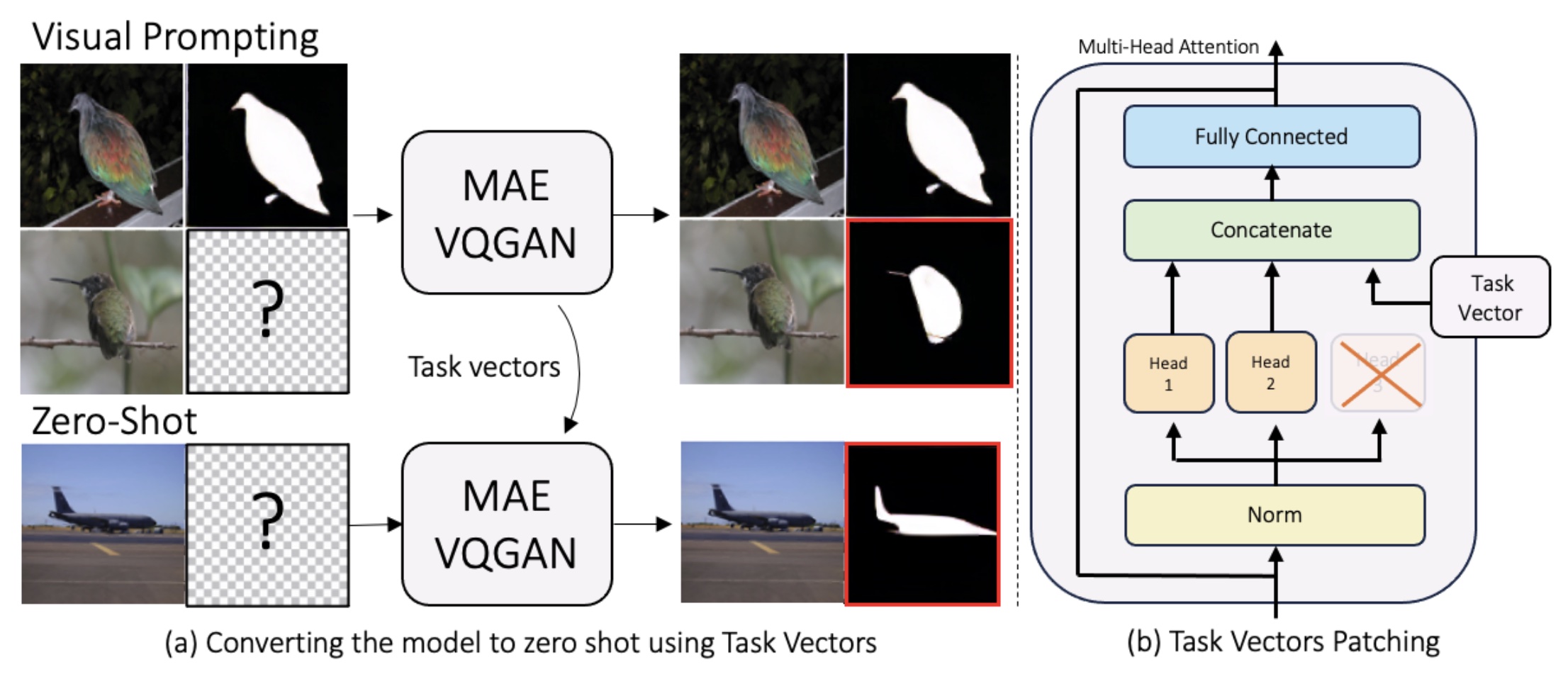
Finding Visual Task Vectors
- Replace attention heads with “task vectors”, that allow few-shot computer vision models to become zero-shot models.
- Paper
- GitHub
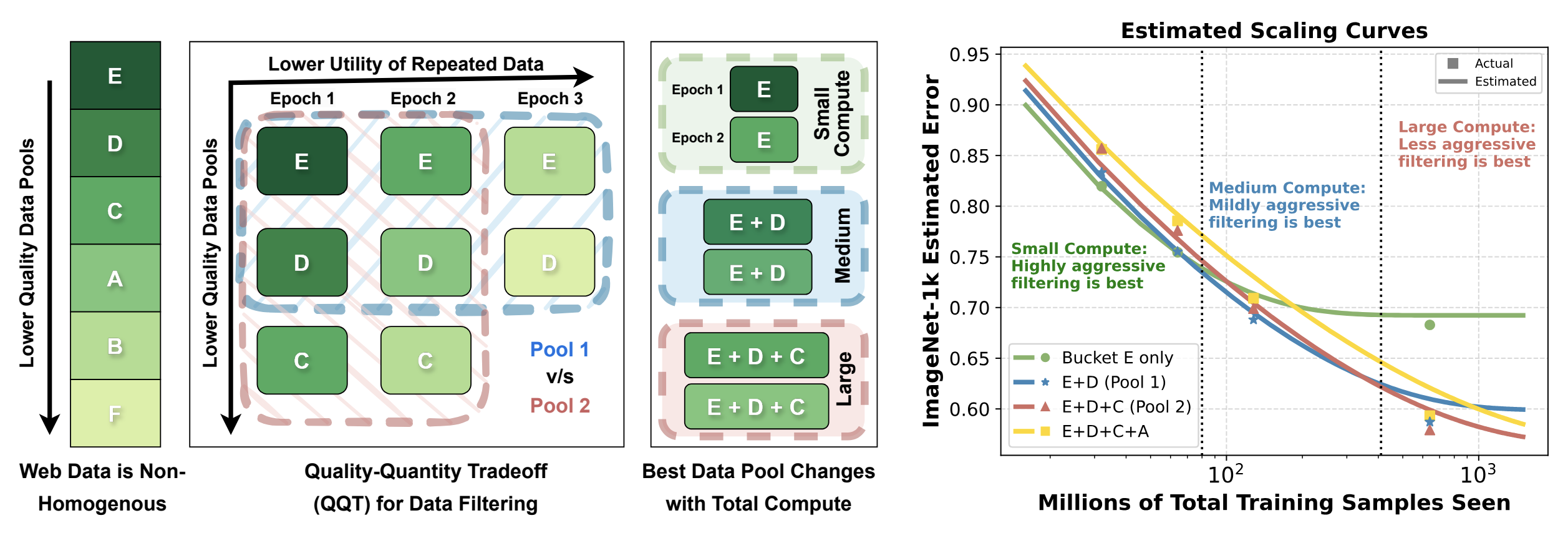
Scaling Laws for Data Filtering
- Explores the tradeoff between compute, quality of data, and number of times each sample is seen during training (a.k.a epochs).
- Paper
- GitHub
Rho-1: Not All Tokens Are What You Need
- Train on only the “important” tokens:
- Train a reference model on all tokens.
- Compute the reference model’s loss for every token in the dataset.
- Train the target model on the tokens where it has a higher loss than the reference model.
- Paper
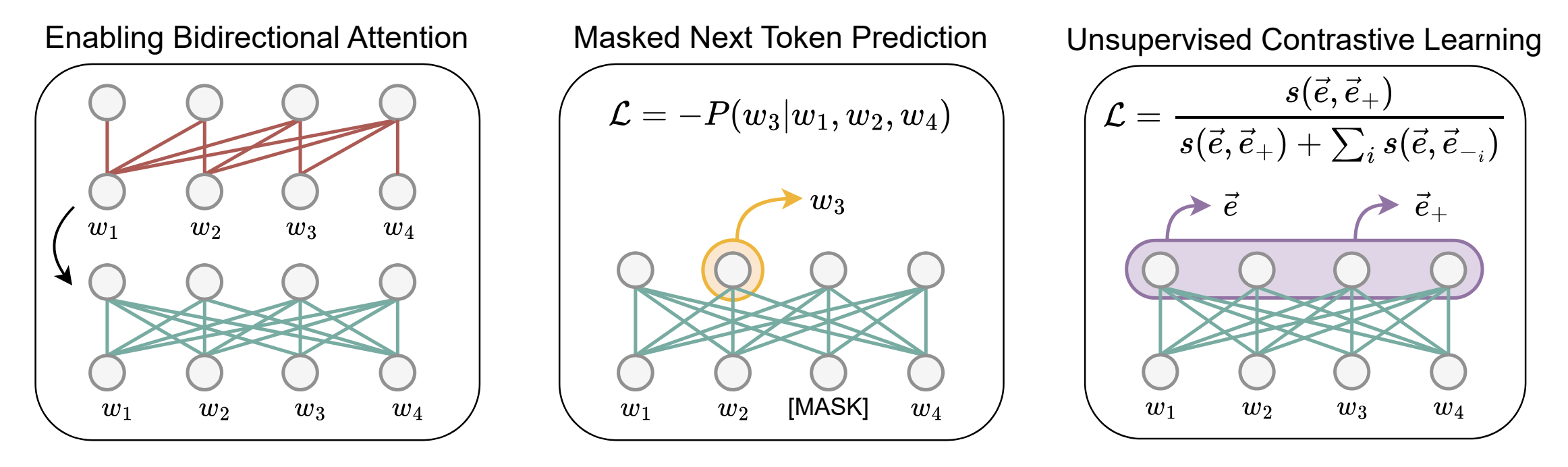
LLM2Vec
- Introduces a method for transforming any decoder-based LLM into a text embedding model.
- Paper
SpatialTracker
- Improved point-tracking in videos by modeling scenes in 3D.
- Project page
- Paper
![]()
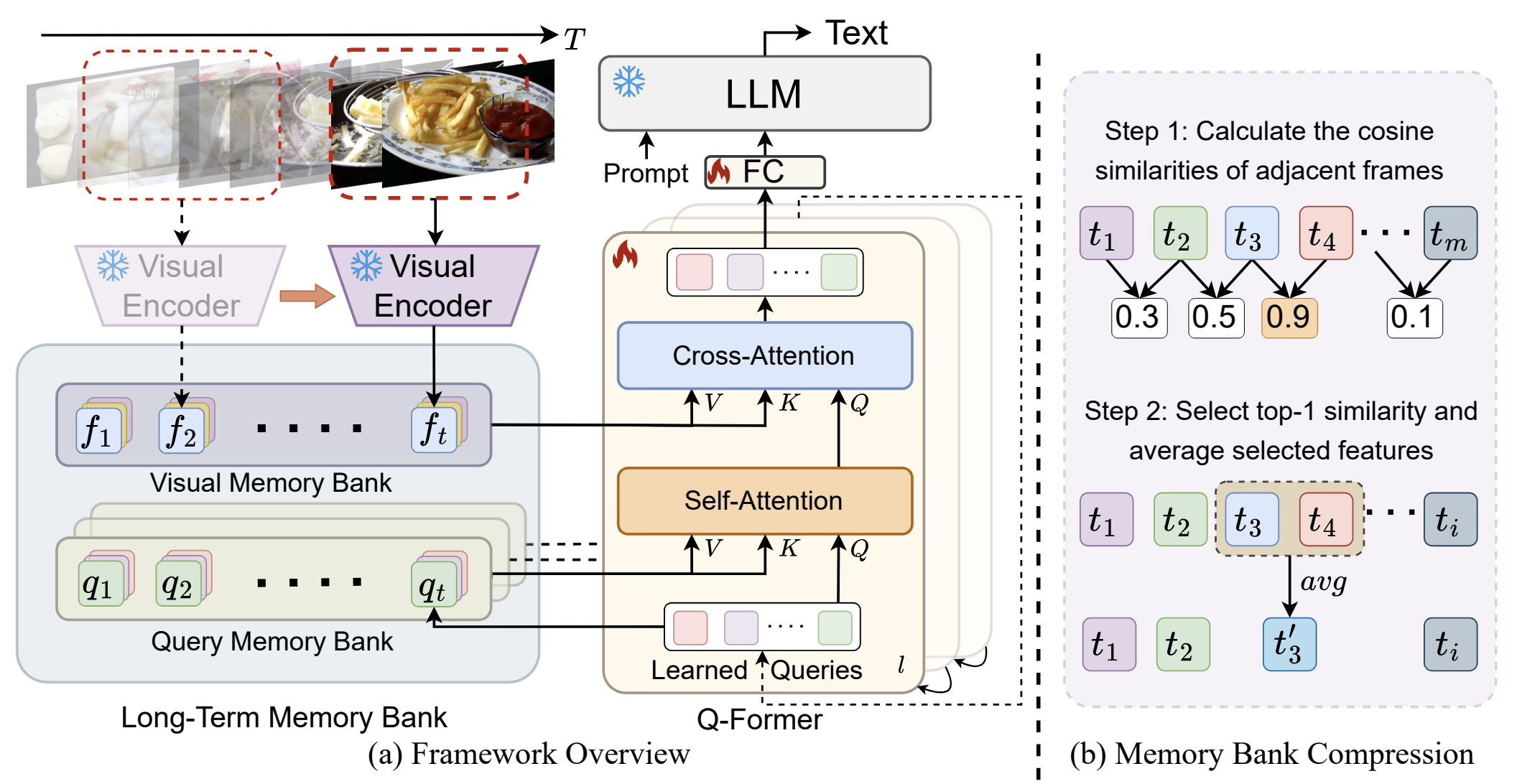
Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
- Store visual features of past frames in a compressed memory bank. Results in significantly less memory consumption when applying multimodal models to long videos.
- Project page
- Paper
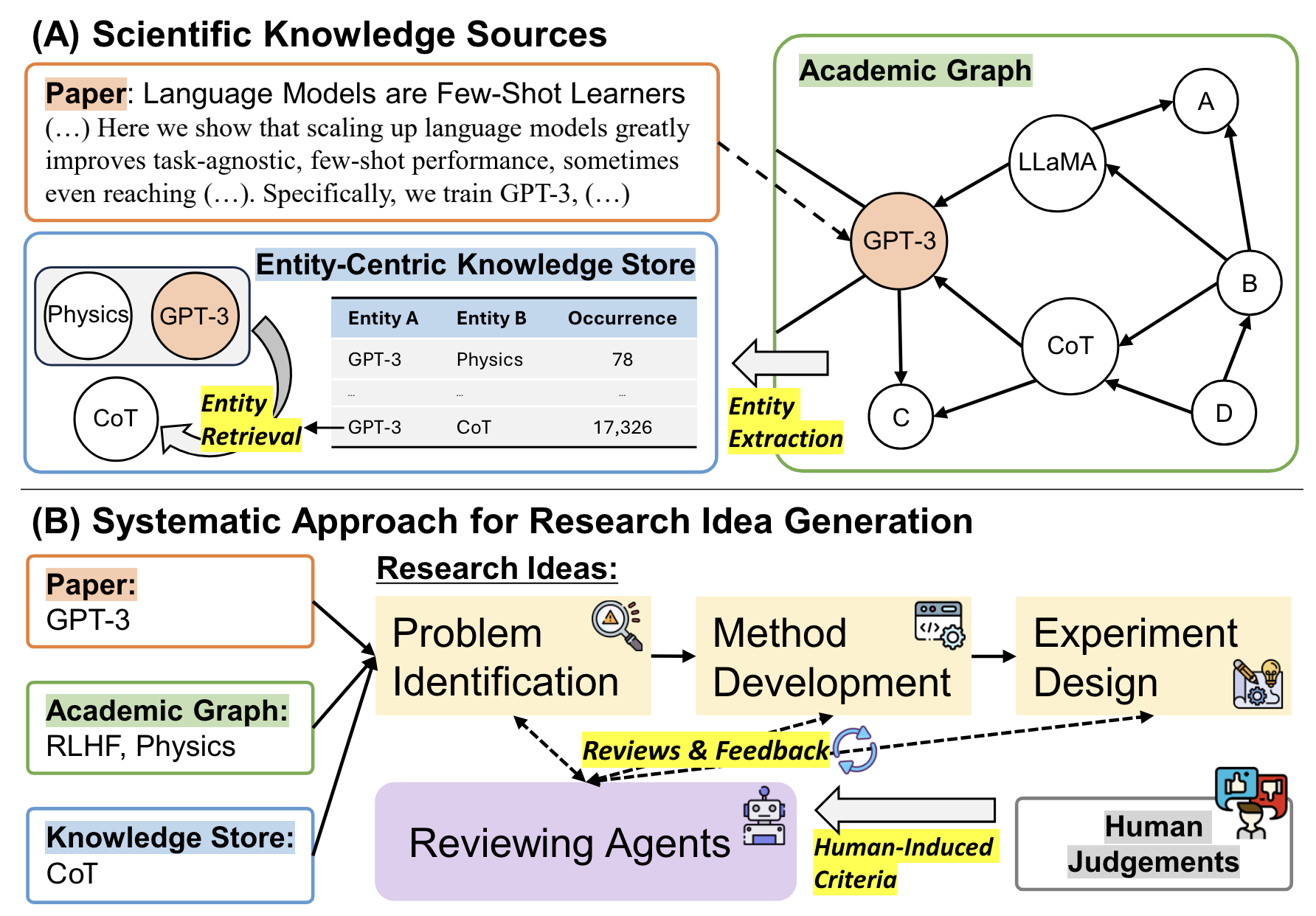
ResearchAgent
- An LLM agent that “automatically generates problems, methods, and experiment designs”.
- Paper
New GPT-4 Turbo
The latest iteration of GPT-4 Turbo outperforms Claude 3 on various benchmarks.
Mistral 8x22B
A 176 billion parameter model released by Mistral.
Rerank 3
- Cohere announced Rerank 3, their latest model for ranking documents for retrieval augmented generation.
- Announcement
Udio
- An impressive new AI-generated-music app.
- Announcement
MTIAv2
- Meta announced version 2 of the Meta Training and Inference Accelerator (MTIA).
- Announcement
Stay up to date
Interested in future weekly updates? Stay up to date by joining our Slack Community!