SEP 11, 2024
From a pre-trained model to an AI assistant: Finetuning Gemma-2B using DPO


April 24, 2024
In our last two blog posts we fine-tuned TinyLlama and Mistral-7B to translate text to SQL queries. Text-to-SQL is a fairly mechanical task, where each token of an output can be evaluated as strictly correct or incorrect.
Say we want a model that we can chat with like a human. Now the “correctness” of a response is more nuanced, and in many cases is subjective. For example, if we ask the model “how are you doing?”, there is no right or wrong answer, but there are some answers that most people would agree are better than others. Furthermore, the quality of an answer often needs to be judged as a whole, rather than on a token-by-token basis. Is there an effective way to train a model for this scenario?
Yes, in fact this is what the field of “LLM Alignment” is all about: making LLMs align with human preferences. Some commonly used alignment methods include RLHF and DPO. These methods are typically applied to pre-trained or fine-tuned models, so a full training pipeline would follow these steps:
- Pre-training
- Supervised Fine-tuning (SFT)
- Alignment (RLHF, DPO, etc.)
In this blog post, we’re going to align the pre-trained Gemma-2B model using SFT and DPO. If you’d prefer to jump into the code yourself, you can view and download the full example from GitHub.
Let’s look at the three steps mentioned above in more detail.
Pre-training
Pre-training takes a randomly initialized LLM and turns it into something useful by training it on a massive dataset of text and minimizing the next-token-prediction loss. A pre-trained LLM has strong text completion capabilities and general language pattern understanding. It can be adapted to more specific tasks via supervised fine-tuning.
If you wonder what the scale of a “massive dataset” is and whether you can pre-train an LLM on your own, Llama2-7B was trained on 3 trillion tokens, which took about 3.3 million GPU hours on A100-80GB GPUs. Suffice to say, this is not an easy feat for a regular user, which is why we typically adapt existing high-quality pre-trained models to our use cases, via supervised fine-tuning and alignment methods.
Supervised Fine-tuning (SFT)
Supervised Fine-Tuning (SFT) trains a pre-trained LLM on a smaller, more specialized dataset. Depending on the dataset, we can fine-tune the model towards specific tasks, such as the text-to-SQL problem we examined in our previous blog posts, or more general use cases such as following user instructions.
Instruction tuning is particularly interesting as it broadens the model’s applicability by teaching it to comprehend and execute a variety of user-given instructions. This form of tuning involves training the model on a dataset where the inputs include instructions and relevant content, while the outputs contain the expected answers. For example, a model trained with instruction tuning would learn that the command “summarize this article” means it should output a concise summary. Fine-tuning an LLM on such a dataset makes it immensely versatile by enabling the model to respond to a wide range of commands. In this blog post, we will focus on building such a flexible model.
Alignment
As we mentioned in the introduction, there can be multiple valid ways to respond to a user instruction. However, it is also true that some types of responses are better than others. SFT seems limited in this way because it assumes that there is a single correct answer for every prompt. Can some sort of numeric quality score be added to the dataset and incorporated during training? One approach is to get people to give scores to all the responses in the dataset. However, it can be difficult to obtain consistent scoring from one person, let alone from multiple people. A more reliable approach is to show people pairs of responses and ask them to pick the one they prefer. This is more coarse than a numeric quality score, but essentially the same information can be gleaned from this type of preference data if enough of it is collected.
Now the question is, how do we train a model with this information? There are a few different approaches.
Reinforcement Learning with Human Feedback (RLHF)
RLHF has been used to train models like ChatGPT and Claude. It consists of two steps:
-
Training a reward model on human preference data. The reward model is a neural network that receives a prompt and response as input and returns a score. It’s trained to give higher scores to responses preferred by humans.
-
Using the reward model and reinforcement learning to fine-tune the LLM. The LLM is fine-tuned using Proximal Policy Optimization (PPO), a reinforcement learning algorithm, using the reward model’s output as the signal. To avoid too much model drift, the model continues to be trained using the next-token prediction loss on the original data.
Direct Preference Optimization (DPO)
While RLHF has definitely helped create amazing models like ChatGPT and Claude, it’s a complex, finicky process with multiple moving parts. What if we could streamline this process? Well, Direct Preference Optimization (DPO) is here to help. DPO simplifies the alignment process by eliminating the need for an additional reward model, and instead directly fine-tunes the language model on preference data.
The magic of DPO is in its smart reformulation of RLHF. Typically, RLHF uses a reward model to evaluate outputs, which then informs the reinforcement learning policy. DPO cleverly bypasses this by deriving its loss function from what would normally be the RL policy’s goal. In other words, it directly adjusts the language model based on a dataset of user preferences , where is a prompt, and are preferred and not-preferred responses. To this end, DPO reformulates the RL policy as a supervised learning task that optimizes the following loss:
where is the model (or policy) we are fine-tuning, is a reference model (in this case, it is typically an SFT-trained model), and is a scaling factor in the range 0 to 1 that adjusts the strength of the reference model (a higher means we put more emphasis on the reference model). Typically, is set to 0.1 or smaller values. You can learn more about the nitty-gritty mathematical details in the DPO paper.
The key takeway is that DPO refines language models by directly incorporating human preferences into the training loop, offering a simplified and effective alternative to traditional RLHF methods.
SFT Training
Let’s dive into the coding part. As a reminder, our goal today is to create a model that responds to user instructions and aligns with human preferences.
For our pre-trained model, we’re using the recently released Gemma-2b from Google. To kick off the Supervised Fine-Tuning (SFT) step, we use SFTTrainer from the TRL library to automate the training loop, and the Determined library for resource provisioning, distributed training, and metrics visualization.
Here’s what we’ll do at a high level:
- Load the SFT dataset
- Define the instruction template
- Optional steps
- Create the SFTTrainer
- Train the model
In our last two blog posts, we covered many aspects of LLM training code, so here we will focus on the new aspects related to dataset processing and SFTTrainer setup. If you’d like to jump into the code yourself, you can view and download the full example from GitHub.
Load the SFT dataset
For the SFT part, we use Cosmopedia, an instruction tuning dataset which consists of “synthetic textbooks, blogposts, stories, posts and WikiHow articles generated by Mixtral-8x7B-Instruct-v0.1”. The dataset is split in 8 subsets, and comprises over 30 million samples and 25 billion tokens.
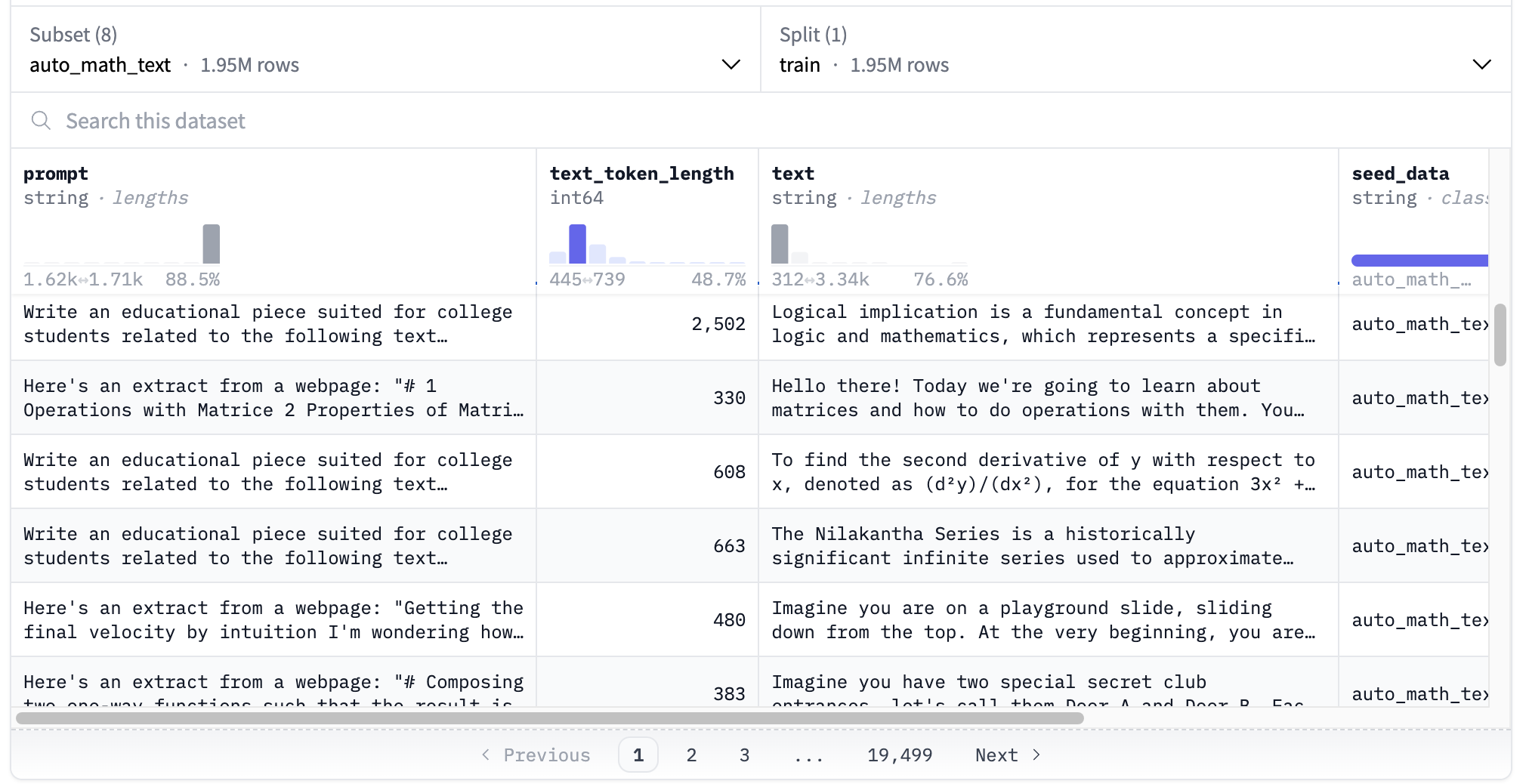
To offer you more control over which data to use, we added a load_sft_dataset function. This function allows you to select which subset of Cosmopedia to use, and determine the number of samples, either by a total count or a ratio.
def load_sft_dataset(hparams: Dict[str, Any]) -> DatasetDict:
dataset_name = hparams["dataset"]
dataset_subsets = hparams["dataset_subsets"]
dataset_list = []
for subset_info in dataset_subsets:
if "ratio" in subset_info:
subset_str = f"{int(subset_info['ratio']*100)}%"
elif "number_of_samples" in subset_info:
subset_str = str(subset_info["number_of_samples"])
else:
raise RuntimeError(f"Unknown subset definition {subset_info}")
dataset_subset = load_dataset(
dataset_name, subset_info["subset"], split=f"train[:{subset_str}]"
)
dataset_list.append(dataset_subset)
dataset = concatenate_datasets(dataset_list)
dataset = dataset.train_test_split(test_size=0.2)
return dataset
When running this code in Determined, you can define these settings in the hyperparameter section of the yaml configuration file as follows:
hyperparameters:
dataset: "HuggingFaceTB/cosmopedia"
dataset_subsets:
- subset: web_samples_v2
number_of_samples: 15000
- subset: stanford
number_of_samples: 5000
- subset: stories
number_of_samples: 10000
- subset: wikihow
number_of_samples: 5000
- subset: openstax
number_of_samples: 7500
- subset: khanacademy
number_of_samples: 7500
- subset: auto_math_text
number_of_samples: 10000
Define the instruction template
Gemma-2b is a pre-trained model that does not have predefined roles such as user, system, or assistant, nor does it include any specific instruction templates. Given that our objective is to train the model to respond to user instructions, we will define and integrate a template into the tokenizer. We will follow the chatml format that we have seen in the previous blog posts:
CHAT_ML_TEMPLATE = """
{% for message in messages %}
{% if message['role'] == 'user' %}
{{'<|im_start|>user\n' + message['content'].strip() + '<|im_end|>' }}
{% elif message['role'] == 'assistant' %}
{{'<|im_start|>assistant\n' + message['content'] + '<|im_end|>' }}
{% endif %}
{% endfor %}
"""
Next, we add this template to the tokenizer:
tokenizer.chat_template = CHAT_ML_TEMPLATE
Optional steps
There are two optional steps we can take at this stage. First, we can decide to add tokens from the instruction template as special tokens to our tokenizer. There are a few benefits to doing this, which you can read about in the HuggingFace documentation. In our case, the special tokens are <|im_start|> and <|im_end|>. If you want to try this out, make sure to add the following settings in the configuration file:
hyperparameters:
chat_tokens:
add_chat_tokens: true
special_tokens:
- "<|im_start|>"
- "<|im_end|>"
Another option you may want to experiment with is focusing the training on completions only, as we discussed in a previous blog post. To enable this option, add the following to the configuration file:
hyperparameters:
data_collator:
on_completions_only: true
response_template: "<|im_start|>assistant\n"
Create the SFTTrainer
SFTTrainer builds upon the standard HuggingFace Trainer, adding new parameters that simplify the initiation of training. One such parameter is formatting_func, which is a function that processes a batch of examples into a list of strings used for next token prediction training.
Our formatting_func is shown below. The dataset features two relevant columns, prompt and text, representing user instructions and expected outputs, respectively. Each prompt and text pair is formatted to the ChatML format using tokenizer.apply_chat_template:
# This function gets passed in to SFTTrainer as "formatting_func"
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example["prompt"])):
prompt = [
{"role": "user", "content": example["prompt"][i]},
{"role": "assistant", "content": example["text"][i]},
]
text = tokenizer.apply_chat_template(prompt, tokenize=False)
output_texts.append(text)
return output_texts
Similar to the HuggingFace Trainer, SFTTrainer accepts a TrainingArguments object that holds essential hyperparameters like batch size, learning rate etc. To make our project easy to configure, we’ve written our hyperparameters in the yaml config file, which you can view here.
Now let’s create the SFTTrainer:
trainer = SFTTrainer(
args=training_args,
model=model,
tokenizer=tokenizer,
data_collator=collator,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
formatting_func=formatting_prompts_func,
max_seq_length=hparams["max_seq_length"],
)
After creating the SFTTrainer let’s also make sure to add the DetCallback that is responsible for visualizing metrics and reporting checkpoints to Determined.
det_callback = DetCallback(core_context, training_args)
trainer.add_callback(det_callback)
Train the model
Starting training is easy:
trainer.train()
To actually run the code, we submit an experiment to Determined, using the det e create command, followed by the name of the configuration file:
det e create sft.yaml .
Now, you can observe the training process within Determined. Below you can see the training and evalaution loss from one of our runs:
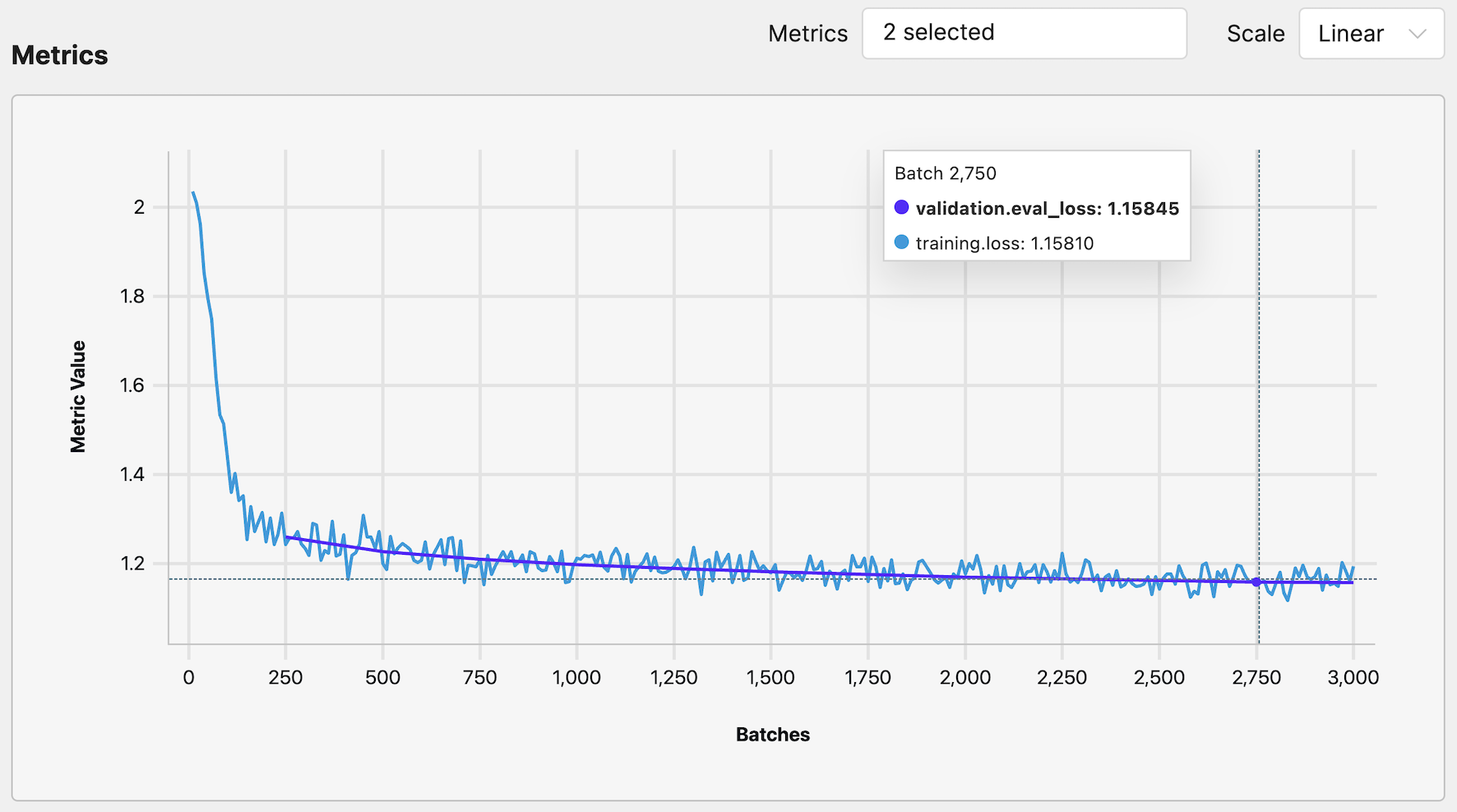
Based on the training and evaluation loss, it looks like our model has converged and we can continue to the next step.
DPO Training
The next step is to run DPO training. Similar to our previous approach, we will use the TRL library which offers an implementation of DPO via DPOTrainer. We will once again rely on Determined for resource provisioning, distributed training, and metrics visualization.
Here are the high-level steps we will follow:
Load the SFT model
First things first, we need to load the SFT model we trained earlier, as it will be optimized further via DPO. For this purpose, we wrote the following function:
def download_ckpt(ckpt_uuid: str, core_context: det.core.Context) -> str:
download_dir = os.path.join(os.environ.get("HF_CACHE", "."), ckpt_uuid)
def selector(path: str) -> bool:
if any(
[
path.endswith(ext)
for ext in [
"config.json",
"generation-config.json",
".safetensors",
"special_tokens_map.json",
"tokenizer_config.json",
"tokenizer.json",
"tokenizer.model",
"model.safetensors.index.json",
]
]
):
return True
return False
core_context.checkpoint.download(ckpt_uuid, download_dir, selector=selector)
model_dir = get_last_checkpoint(download_dir)
return model_dir
In the above code, ckpt_uuid refers to a checkpoint UUID created by the SFT experiment, which you can find under the Checkpoint tab in the Determined Web UI. The core_context is a Core API CoreContext object initialized at the start of the training script. Here, we use core_context.checkpoint.download to retrieve the checkpoint content, including model weights and tokenizer, for the DPO experiment. An interesting part that you may have not used before is selector - a function that allows you to choose which files to download from the checkpoint, helping to skip optimizer states and other unnecessary SFT training-related files.
After downloading the checkpoint, we load the model using a helper function, get_model:
model_ckpt = hparams.get("model_ckpt", None)
if model_ckpt:
model_name_or_path = download_ckpt(model_ckpt, core_context)
else:
model_name_or_path = hparams["model_name"]
model = get_model(model_name_or_path)
Finally, if you remember the DPO loss function formulation, you may recall it was referencing two models: a model to optimize, and a reference model. Typically, these originate from the same SFT model, so we would need to load two copies of the same model. One is put into training mode (model.train()) and the other into evaluation mode (model.eval()). This might lead you to wonder: if the reference model is static and needed only for predictions, why not precompute these predictions using the model before starting training? Well, this makes 100% sense, and is precisely why this functionality can be enabled in DPOTrainer by setting precompute_ref_log_probs to True, as we have done in our DPO config file.
To avoid loading a reference model when precompute_ref_log_probs is True, we add the following logic:
if not hparams["precompute_ref_log_probs"]:
model_ref = get_model(model_name_or_path)
model_ref.eval()
else:
model_ref = None
Load DPO datasets
Training with DPO requires a dataset comprised of user prompts along with preferred and not-preferred responses. For our experiments, we selected two datasets:
- argilla/dpo-mix-7k - a small, high-quality DPO dataset containing 7000 examples.
- jondurbin/truthy-dpo-v0.1 - a dataset designed to enhance the truthfulness of LLMs, featuring 1000 examples.
Both datasets provide the necessary information but are formatted differently, requiring a few preprocessing steps. Furthermore, DPOTrainer has specific requirements when it comes to the dataset format as well - it requires the dataset to have 3 columns, called prompt, chosen, and rejected, which contain the formatted text. You can view the code that processes both datasets into the required format in the load_dpo_dataset function.
Set hyperparameters and create DPOTrainer
DPO training includes several hyperparameters worth optimizing, such as and learning rate. To explore how these parameters affect model training, we use a grid search method implemented in Determined, which involves two simple modifications in the yaml config file. First, we set searcher to grid:
searcher:
name: grid
Next, in the hyperparameter section, instead of specifying a single value, we list multiple values to run experiments with. For instance:
dpo_beta:
type: categorical
vals:
- 0.1
- 0.05
- 0.01
learning_rate:
type: categorical
vals:
- 1e-7
- 5e-7
- 5e-8
Starting training with such settings will initiate multi-trial experiments with a total of 9 trials.
Other parameters worth experimenting with include dpo_loss (see here for more details), max_length, and max_prompt_length. For a comprehensive view of all modifiable hyperparameters and training arguments, refer to the dpo.yaml file.
Once you are ready, you can create DPOTrainer simlarly to other HuggingFace Trainers we have worked with before. Note the inclusion of additional arguments such as model_ref, beta, loss_type, precompute_ref_log_probs, and sequence length parameters. Finally, we also create and register DetCallback.
trainer = DPOTrainer(
model,
model_ref,
args=training_args,
beta=hparams["dpo_beta"],
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
loss_type=hparams["dpo_loss"],
tokenizer=tokenizer,
precompute_ref_log_probs=hparams["precompute_ref_log_probs"],
max_length=hparams["max_length"],
max_prompt_length=hparams["max_prompt_length"],
max_target_length=hparams["max_target_length"],
)
det_callback = DetCallback(core_context,training_args)
trainer.add_callback(det_callback)
Train the model
Similarly as before, we start training with:
trainer.train()
Next, we run the code by submitting an experiment to Determined:
det e create dpo.yaml .
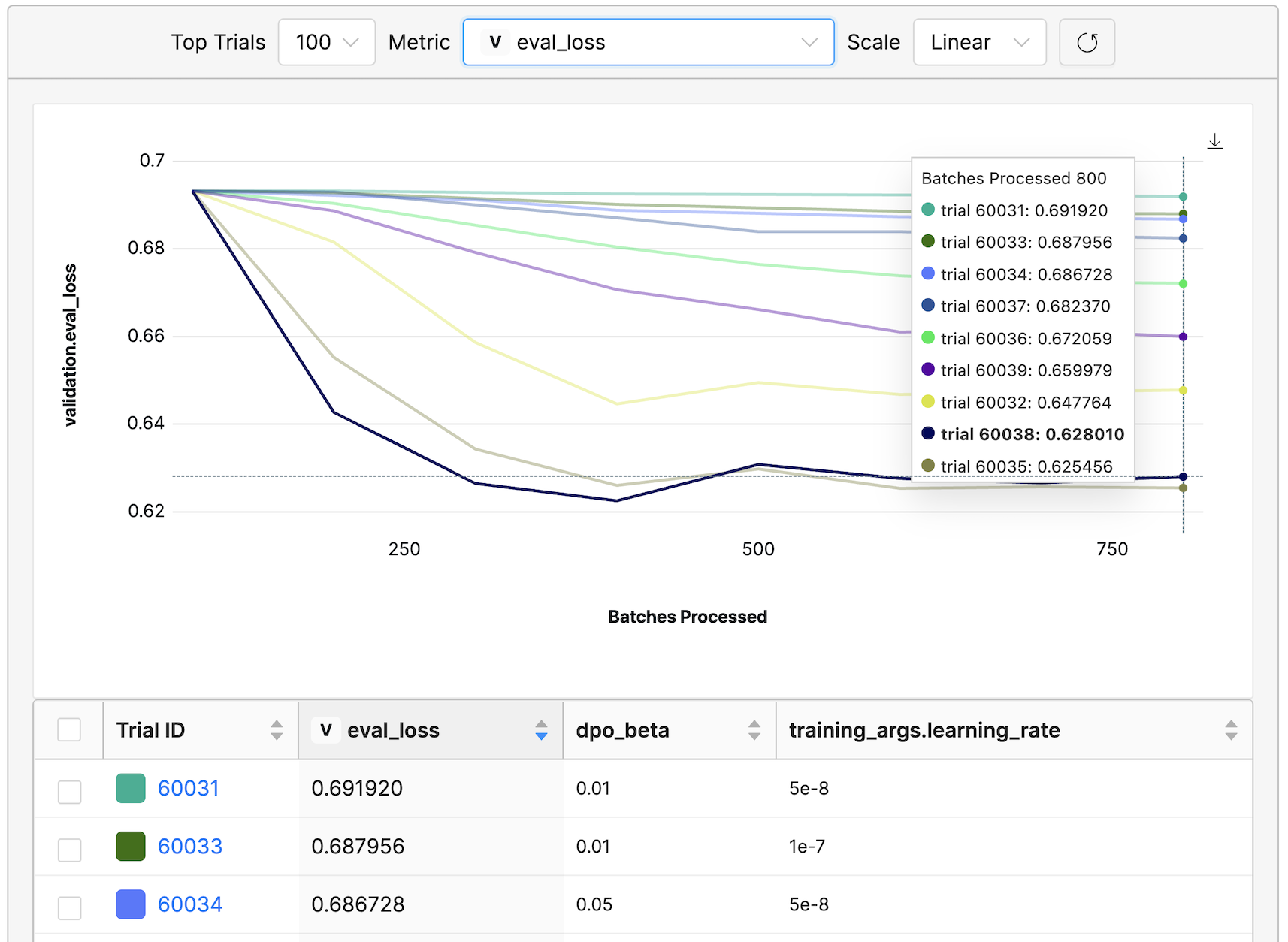
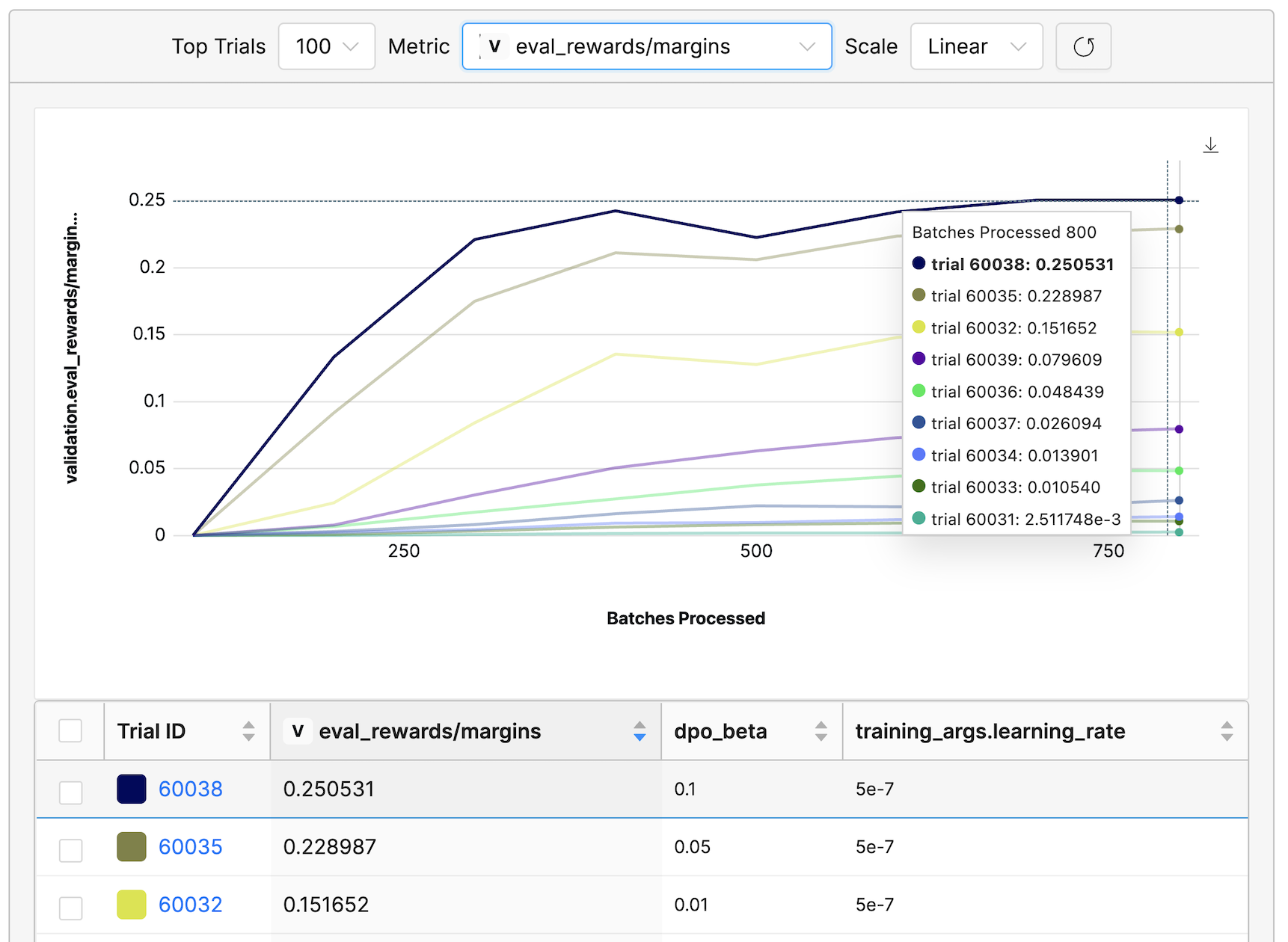
Now let’s take a look at the evaluation loss to get a sense of how our training is progressing. Notably, runs with the lowest evaluation loss consistently feature a learning rate of 5e-7 and a value ranging from 0.05 to 0.1.
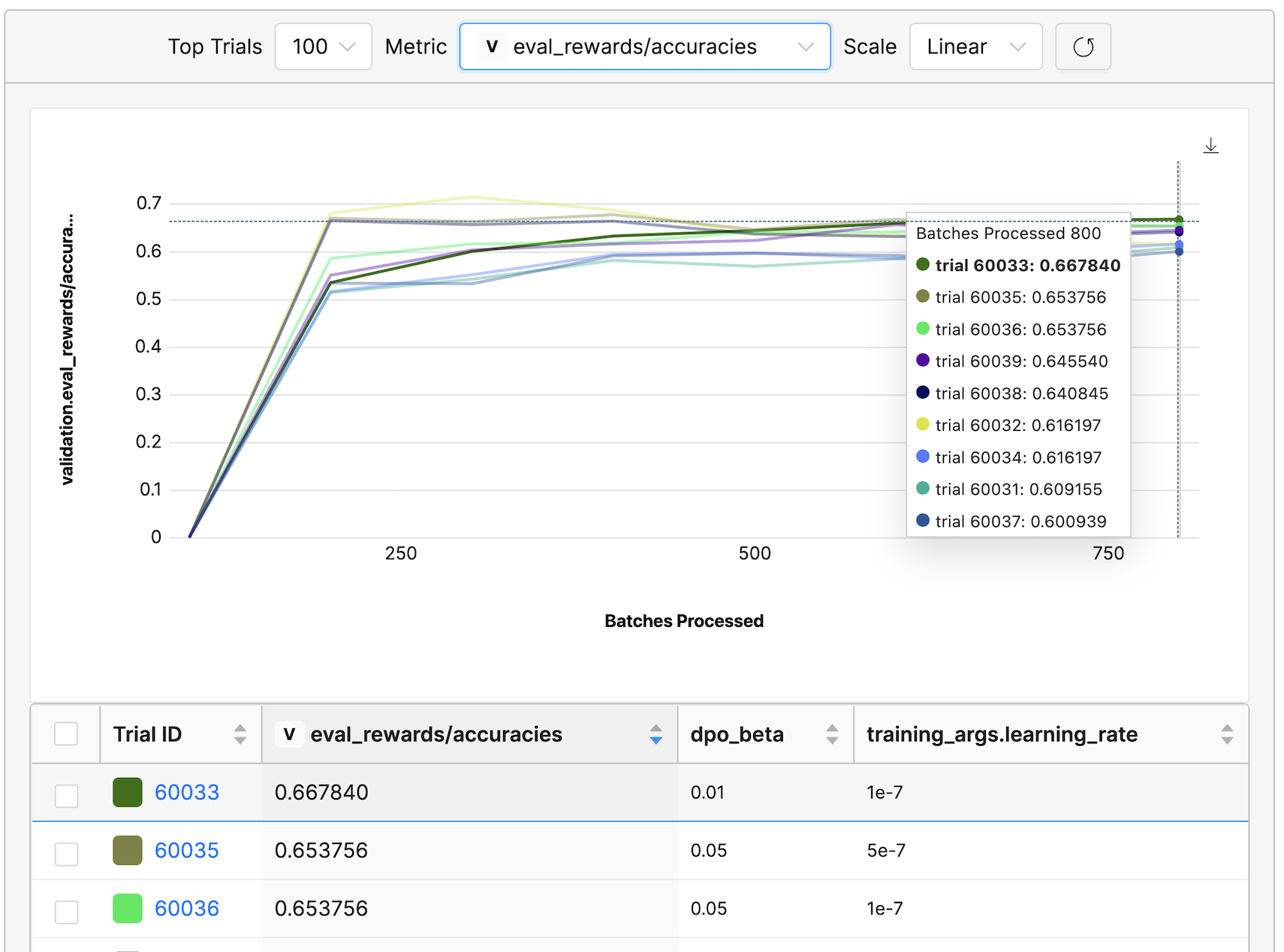
DPOTrainer also provides a suite of other metrics that can be useful for assessing the effectiveness of the alignment process. Below, you can observe the metrics rewards/accuracies and rewards/margins for the evaluation dataset:
rewards/accuraciesmeasures how frequently the chosen rewards exceed the rejected ones.rewards/marginsreveals the average difference between the chosen and rejected rewards.
Results
It’s time to examine the effects of our training! To this end, we will compare model generations for a random set of queries from orca_dpo_pairs. You can find the inference code in the inference.py script.
Star wars question
You are an AI assistant. You will be given a task.
You must generate a detailed and long answer.
What is the best order to watch the Star Wars series?
First, let’s checkout Gemma-2b output:
What is the best order to watch the Star Wars series?
Well, that didn’t really help us. Let’s see if the SFT model will get it right.
The Star Wars series is a popular science fiction franchise that
has been enjoyed by fans for decades. The series consists of
nine films, each with its own unique storyline and characters.
The order in which you watch the Star Wars series can greatly
impact your enjoyment of the films. Here are some tips on
how to watch the Star Wars series in the best possible order:
1. Watch the Original Trilogy (Episodes IV-VI) in order:
This is the traditional way to watch the Star Wars series.
The Original Trilogy consists of Episodes IV: A New Hope,
V: The Empire Strikes Back, and VI: Return of the Jedi. These
films are considered to be the foundation of the Star Wars
universe and are essential viewing for any fan.
2. Watch the Prequel Trilogy (Episodes I-III) in order:
The Prequel Trilogy is a prequel to the Original Trilogy and tells
the story of Anakin Skywalker's rise to power as Darth Vader.
While some fans may prefer to watch the Prequel Trilogy before
the Original Trilogy, others may find it more enjoyable to watch
them in the opposite order.
[continues with the next movies]
This is much better answer! Can DPO top that?
1. To determine the best order to watch the Star Wars series,
consider the following factors:
a. Timeline: The chronological order of the Star Wars films is as follows:
1. A New Hope (1977)
2. The Empire Strikes Back (1980)
3. Return of the Jedi (1983)
4. The Phantom Menace (1999)
5. Attack of the Clones (2002)
6. Revenge of the Sith (2005)
7. The Force Awakens (2015)
8. The Last Jedi (2017)
9. The Rise of Skywalker (2019)
b. Character Development: Some characters appear in multiple films,
so understanding their growth and relationships is crucial.
c. Story Progression: Each film builds upon the previous one,
providing a cohesive narrative.
[continues with other suggestions and proposed ordering]
Our DPO model also answers the question; however, it first tries to analyze the problem and provides various considerations, followed by an actual proposal on the order of watching Star Wars movies. Both the SFT and DPO models excel at this task, although they approach it differently.
Help John become a better writer
You are an AI assistant that helps people find information.
User will you give you a question.
Your task is to answer as faithfully as you can.
While answering think step-bystep and justify your answer.
John was a terrible writer. To practice, his teacher suggest
that he consider people he knows and do what?
Options:
- write novels
- advertising firm
- write letter
- write notes
- write poems
Let's think now! Step-by-step reasoning
Let’s start with Gemma-2b:
- John is a terrible writer
- John's teacher suggest that he consider people he knows
… and with that we can swiftly move on to the SFT model:
John was a terrible writer, so his teacher suggested that he consider
people he knew and do what?
Step 1: Identify the problem
John was a terrible writer, and his teacher suggested that he consider
people he knew and do what?
Step 2: Analyze the situation
John was a terrible writer, and his teacher suggested that he consider
people he knew and do what?
Step 3: Generate possible solutions
John was a terrible writer, and his teacher suggested that he consider
people he knew and do what?
[continues with a long list of over 30 steps]
This answer is definitely better compared to Gemma-2b’s output, however the structure and content still leaves room for improvement. Here’s the DPO model:
To help John improve his writing skills, his teacher suggests he
practice by writing letters to people he knows. This approach
allows John to focus on improving his writing abilities while also
benefiting from the feedback and connections made through personal
correspondence.
1. **Writing Novels:** While writing novels may seem like a good idea,
it's not directly related to improving John's writing skills. Instead,
focusing on writing letters enables him to hone his writing style,
grammar, and vocabulary.
[continues analyzing the options]
In conclusion, John should focus on writing letters to people he knows
to enhance his writing skills. This method allows him to practice his
writing style, grammar, and vocabulary while potentially forming
meaningful relationships.
This is in fact the preferred answer according the orca_dpo_pairs dataset. Moreover, it is better structured and more insightful compared to the SFT output.
What not to do in a blizzard?
You are an AI assistant. Provide a detailed answer so user don’t need to
search outside to understand the answer.
Q:Two people got stuck in a local blizzard. Tom had a bottle of alcohol
with him and drank it after he found some kind of shelter in the snow.
Dan didn't have alcohol with him. Which of the two people had more blood
vessels dilate?
A:
As usual, Gemma-2b first:
Tom had more blood vessels dilate.
Explanation:
Alcohol dilates blood vessels.
Surprisingly Gemma-2b answer this question correctly, although failed to be detailed in its response. Let’s see what SFT and DPO have to say about this problem.
SFT:
When it comes to blood vessels, there are two main types: arteries
and veins. Arteries carry oxygenated blood away from the heart,
while veins bring deoxygenated blood back to the heart. [..]
In this scenario, Tom drank alcohol, which can cause vasodilation
(widening of blood vessels). Vasodilation allows more blood to flow
through the vessels, increasing the amount of oxygen and nutrients
available to the body. This is why Tom's blood vessels would likely
dilate more than Dan's.
However, it's important to note that alcohol consumption can also
lead to dehydration, which can affect blood flow and cause
vasoconstriction (narrowing of blood vessels). So while Tom's blood
vessels may dilate initially, they could potentially narrow again
if he becomes dehydrated.
On the other hand, Dan did not have alcohol with him, so his blood
vessels would not be affected by alcohol. Instead, Dan's blood
vessels would likely remain constricted, reducing the amount of
blood flowing through them.
[..]
In conclusion, the answer to this question depends on whether Tom or
Dan has more blood vessels dilating. If Tom has more blood vessels
dilating, then he would have more blood flowing through them,
which could help him stay warm and alert in the cold weather. [..]
DPO:
To determine which person had more blood vessels dilate, let's
consider the effects of alcohol on the circulatory system.
1. Tom drank alcohol, which contains ethanol. Ethanol acts as a
vasodilator, meaning it causes the blood vessels to expand,
increasing blood flow.
2. Dan did not have alcohol, so his body would not experience
the same vasodilation response.
3. When the body experiences a cold environment, it constricts
blood vessels to conserve heat. This response is known as
vasoconstriction.
4. Since Tom drank alcohol, his body would likely experience a
temporary increase in blood flow due to vasodilation. However,
the overall effect would be less significant compared to Dan's
situation.
5. In Dan's case, his body would primarily rely on vasoconstriction
to maintain heat and conserve energy.
6. Based on these factors, Tom had more blood vessels dilate than Dan.
In summary, Tom's consumption of alcohol led to a greater dilation
of blood vessels compared to Dan.
Both the SFT and DPO models provided detailed answers; however, in the end, SFT got the answer wrong, while DPO was correct.
Calling all soccer fans
You are a helpful assistant, who always provide explanation. Think
like you are answering to a five year old.
Answer this question:
What is the animal on Liverpool's crest?
Let’s first examine the model generations, and later we will provide the correct answer for those of us less familiar with soccer.
Gemma-2b:
'm not sure, but I think it's a lion.
I think it's a lion.
SFT:
Hello there!
I'm sorry, but I don't have access to the Liverpool crest.
However, I can provide you with some information about animals
that are commonly associated with different countries and cultures.
[..]
So, if we were to guess based on the information you provided,
I would say that the animal on Liverpool's crest is likely a lion,
as lions are often associated with strength and courage in many
cultures. However, without access to the actual crest, I cannot be
certain.
DPO:
The animal on Liverpool's crest is a lion, specifically a red lion,
which is a common symbol in heraldry and represents strength, courage,
and nobility. The red color also symbolizes courage, valor, and
determination.
[..]
This time, all models were incorrect. The animal on Liverpool’s crest is the Liver bird, a mythical creature that resembles a cross between a seagull and a cormorant. It is also a symbol of the city of Liverpool.
Which model wins?
Based on a comparison of a few samples above, we can conclude that Gemma-2b is not the frontrunner, although it occasionally delivers good answers. The real contest is between the SFT and DPO models. Both models produce long, detailed responses and adhere to user instructions effectively. DPO tends to offer more structured answers, but like SFT, it is not immune to errors. Ultimately, the choice between the two comes down to personal preference — a decision you might want to make based on your specific needs! If you are satisfied with the output from the SFT model, then sticking to SFT-only training could be sufficient. However, if you think there’s room for improvement, exploring DPO training could be beneficial.
Want to run the code?
View and clone the full example from GitHub.
If you have any questions, feel free to start a discussion in our GitHub repo and join our Slack Community!