SEP 11, 2024
Using Determined’s Model Registry To Simplify Model Deployment

October 13, 2020
Determined AI is excited to announce another key feature that makes it simpler to move ML models from research to production, the Determined Model Registry. Determined enables deep learning engineers to train better models more quickly, via features like easy-to-use distributed training, state-of-the-art hyperparameter tuning, and integrated experiment tracking and visualization. The new model registry allows you to get real value out of those new models by making it easier than ever to move models from research to production. Keeping track of the code, checkpoints, and artifacts needed to run models in production has never been easier.
Bridging the Gap between Research and Production
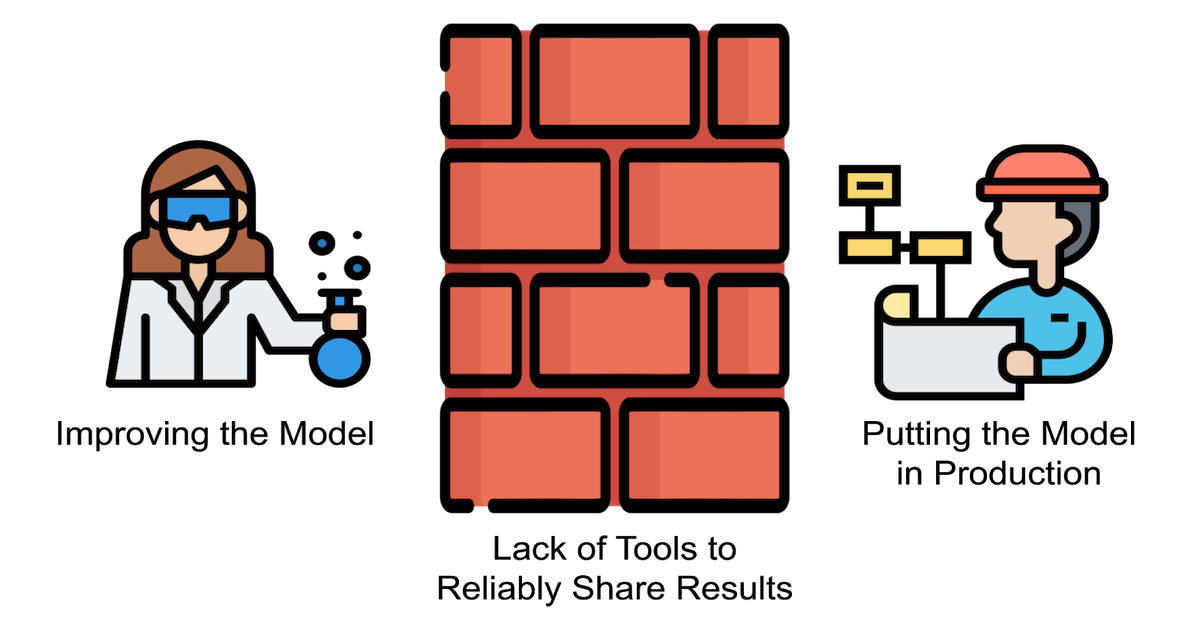
As more and more teams integrate deep learning models into production applications, a common theme we’ve seen is difficulty translating the research done when developing a model into software ready to integrate into an application. These difficulties have created whole communities dedicated to solving “MLOps”, as organizations everywhere try to find solutions to the problems that crop up when productionizing ML. The model registry solves the first crucial problem: coordinating the hand off of a trained model for use in production.
Physically moving a model to production is a surprisingly tricky task. To successfully get a model running in production you’ll need:
- The code that creates the model and loads weights
- The model weights (and possibly other artifacts)
- The full environment to use the model
- Data preprocessing code
The model weights alone can be quite large – easily multiple gigabytes. Coordinating where you’ll store these files, how to initialize the model, and how to load model weights is not straightforward if you don’t have the right tools. Further many production models change all of the time as they are retrained on new data. A manual, hands-on process for promoting models to production just won’t scale.
Production-Ready Models with the Model Registry
The model registry provides a standardized tool to hand off models from development to production. At its core, the model registry is simple: it provides a mechanism to create named “Models” and maintain versions of these models.
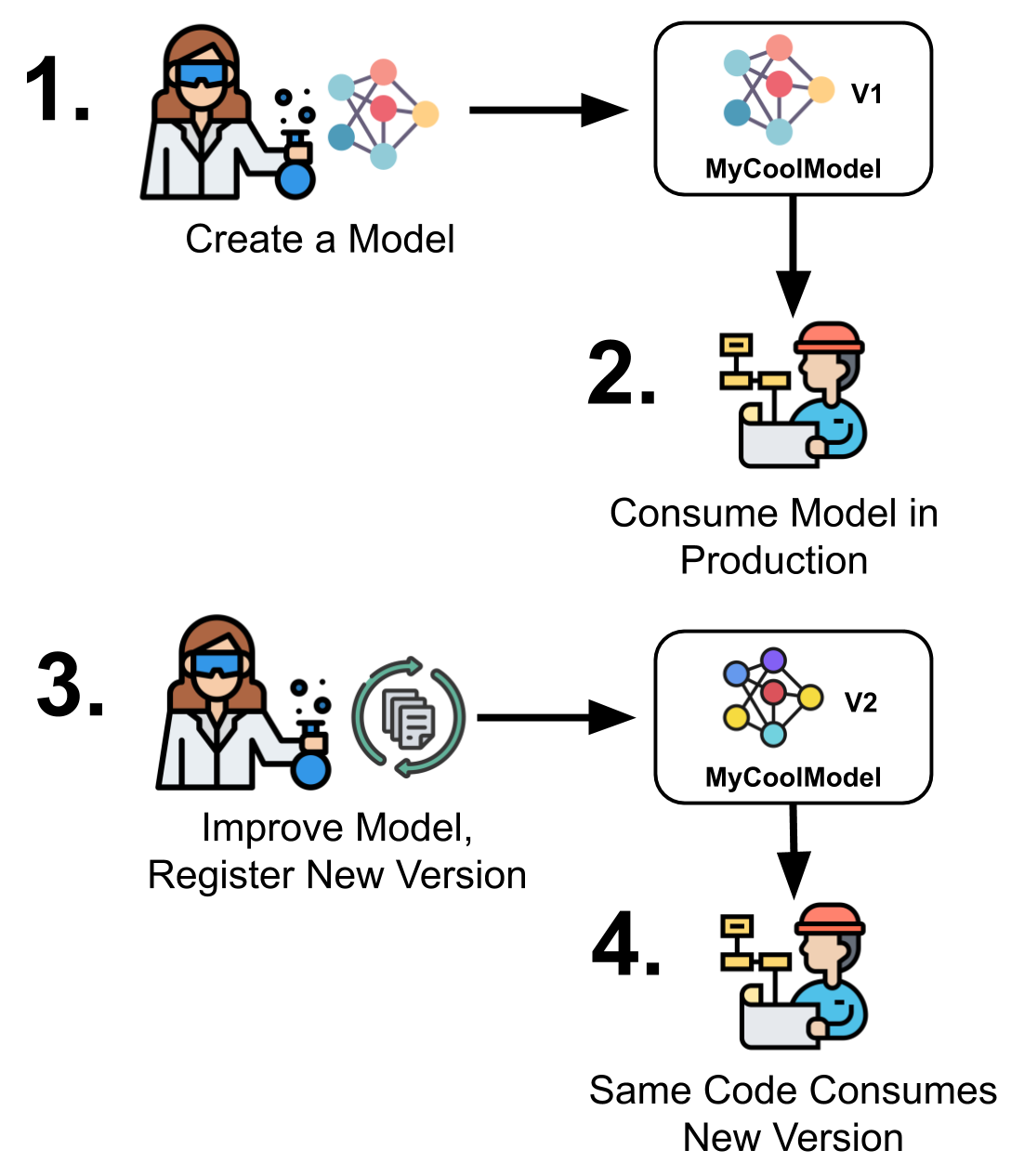
Since Determined tracks and manages your model code, checkpoints, and metrics, this is all incredibly simple – all the data scientist needs to do is mark one of their experiments as a new version of a model and Determined automatically tracks all of the important information needed to use that model in production.
Consuming a model is just as easy – ML engineers can call simple APIs to instantiate a model, load the trained weights, and easily use that model in a production system. If the ML scientist pushes a new version of that model to the repository, the engineer can use the same code as before to load the new version, greatly simplifying the hand off between research and production.
Code Example
Let’s walk through a real example of how to use the Model Registry in practice. You first train a new model in Determined, such as a simple experiment with fixed hyperparameters. Here’s what the resulting trained model looks like in Determined’s WebUI:
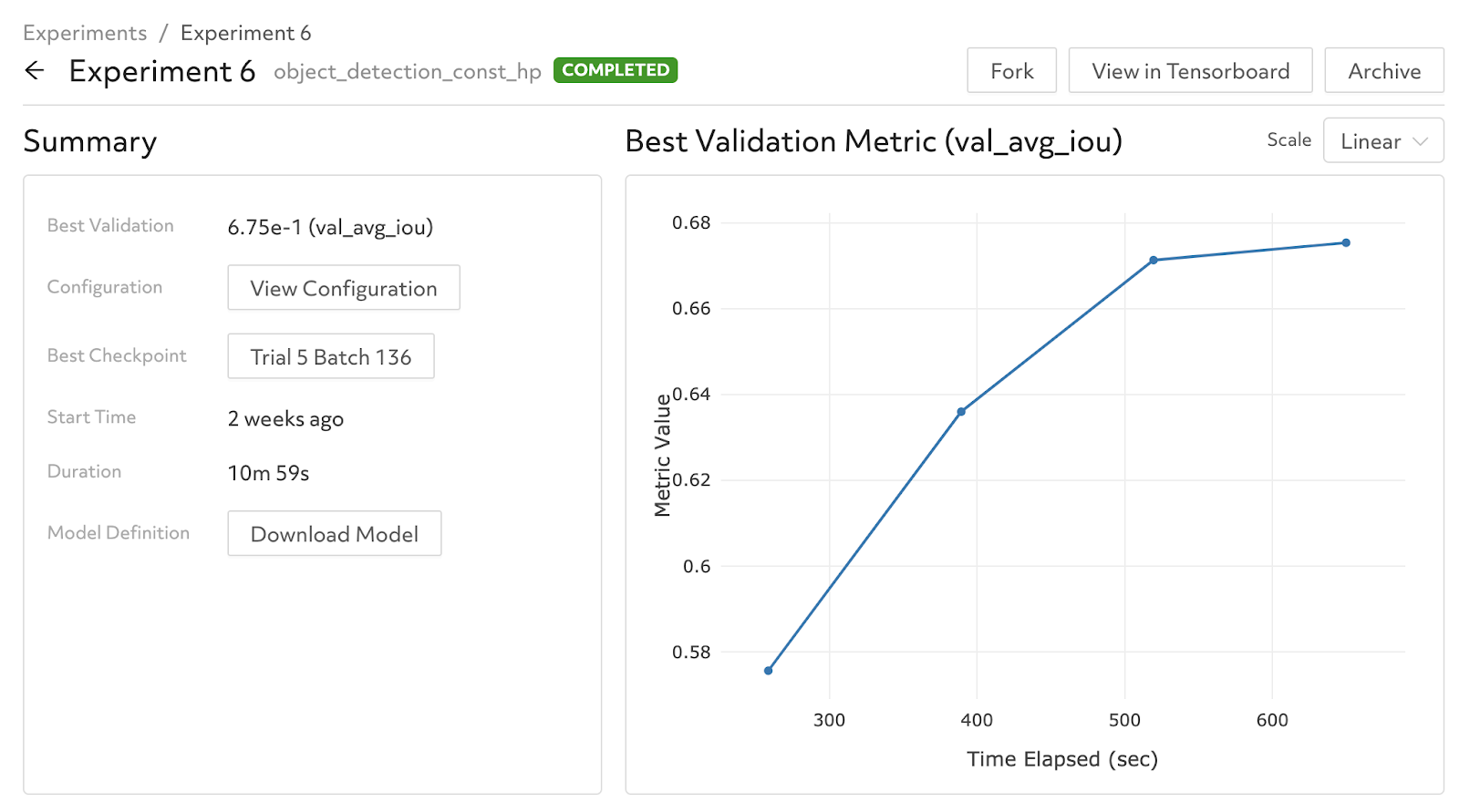
To add this model to the Model Registry:
from determined.experimental import Determined
d = Determined()
model = d.create_model("object-detection")
checkpoint = d.get_experiment(6).top_checkpoint()
model_version = model.register_version(checkpoint.uuid)
Determined provides simple APIs to extract results from your experiments and add them to the Model Registry. Here we name our model “object-detection” and create our first version of that model from the best checkpoint of Experiment 6.
You can then integrate this model into your production system with a simple snippet:
model = Determined().get_model("object-detection")
inference_model = model.get_version().load()
predictions = inference_model.predict(data)
Determined provides simple APIs to retrieve the model and all of the model artifacts, then load that model into memory (including the trained weights). You can use those APIs to integrate models into a wide range of production systems, from high-availability REST endpoints to batch inference systems.
As you continue to update your model, you’ll need a way to keep your production system up-to-date. Say you retrain your model with a hyperparameter search in Determined and get a big jump in performance:
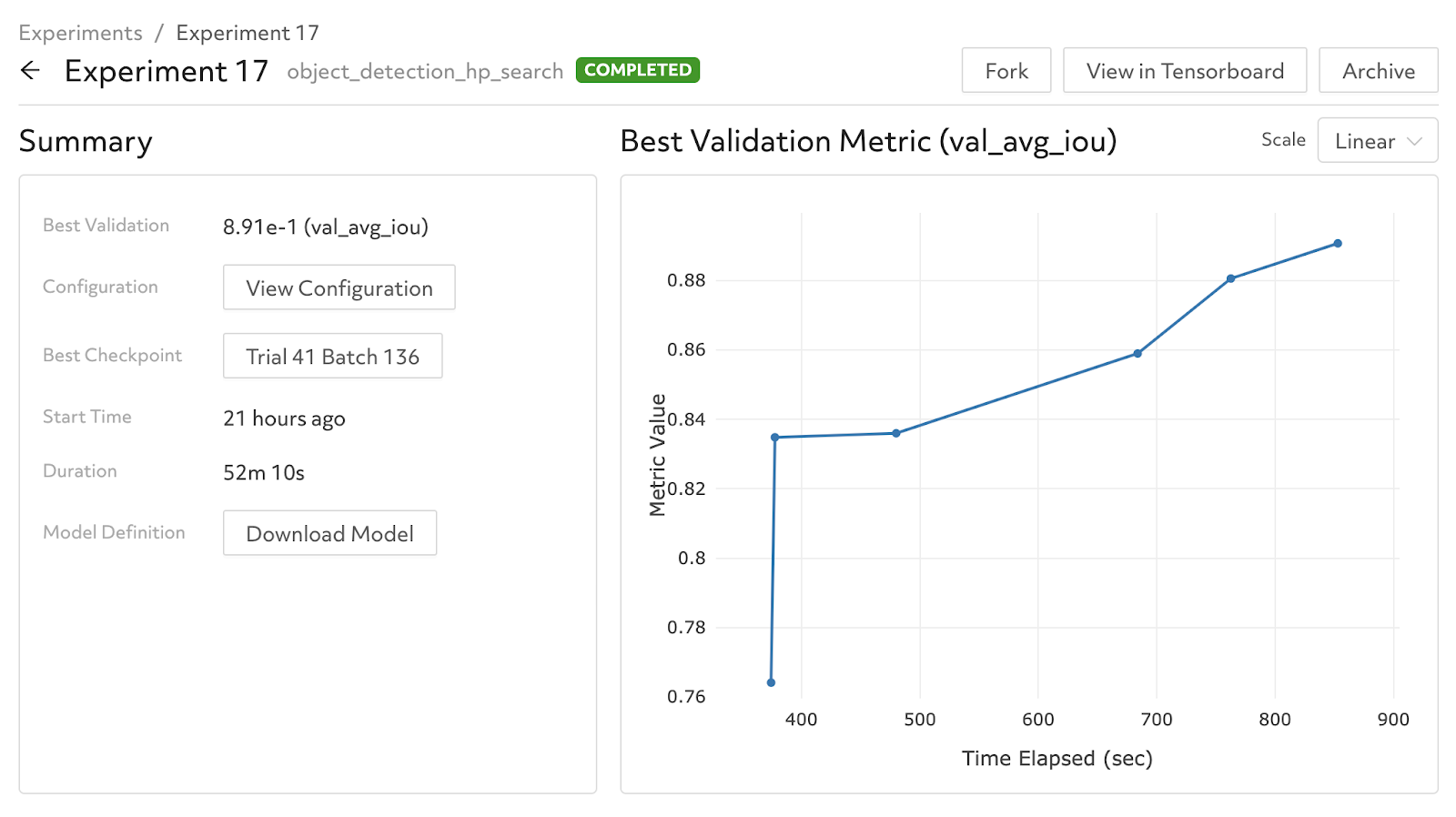
You can tag a new version of the model in the Model Registry:
model = d.get_model("object-detection")
checkpoint = d.get_experiment(17).top_checkpoint()
model_version = model.register_version(checkpoint.uuid)
And your production code above will still work! The production code will communicate with Determined and grab the latest version of the “object-detection” model, and you’ll immediately be able to benefit from the improvements in a production environment.
Check It Out
To get started with Determined, start with our quick start guide! For an example of the Model Registry in a real-world workflow, check out our Kubeflow Pipelines example.
If you have any questions along the way, hop on our community Slack or visit our GitHub repository; we’re happy to help out!