Posts in: Tutorials
Weekly updates from our team on topics like large-scale deep learning training, cloud GPU infrastructure, hyperparameter tuning, and more.
SEP 11, 2024
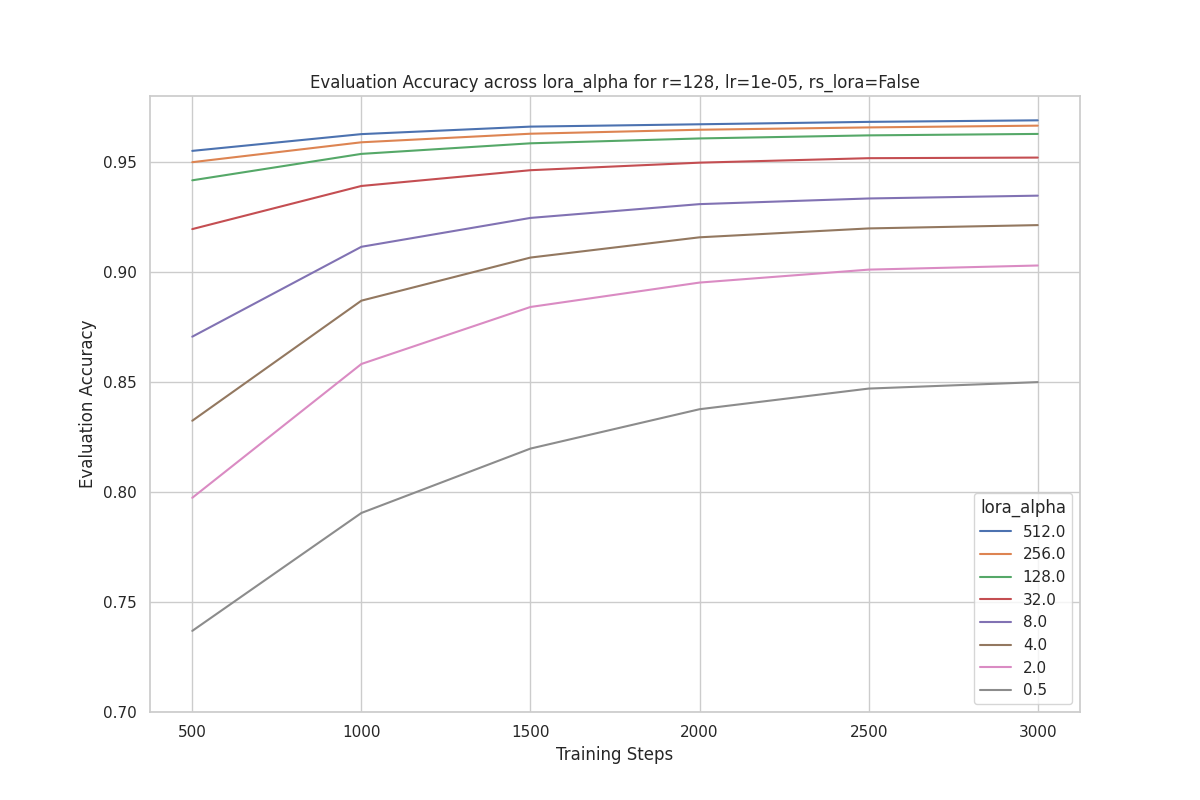
Finding the best LoRA parameters
How alpha, rank, and learning rate affect model accuracy, and whether rank-stabilized LoRA helps.
JUL 10, 2024
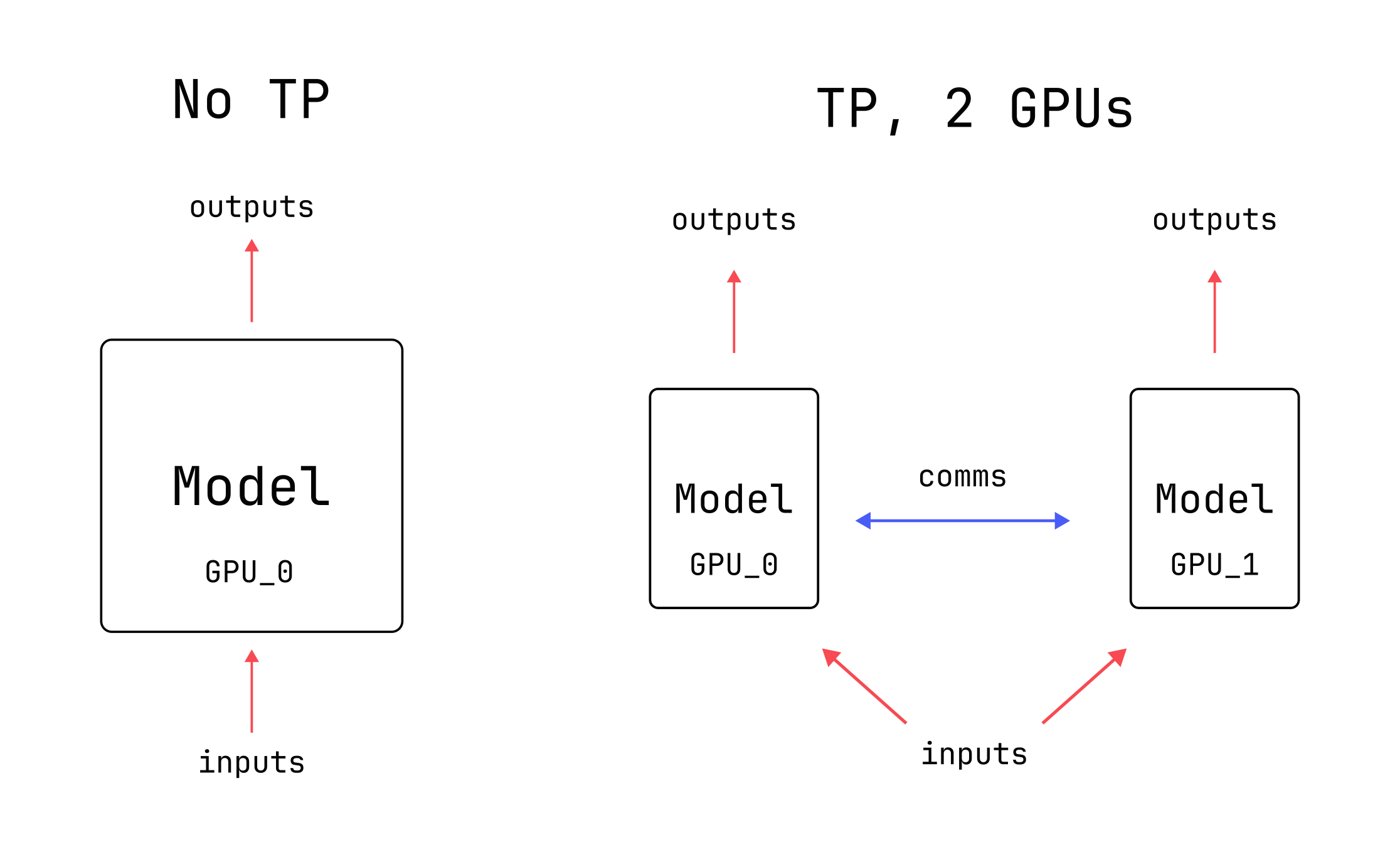
Tensor Parallelism in Three Levels of Difficulty
Tensor parallelism, from beginner to expert using PyTorch.
JUN 12, 2024
Activation Memory: A Deep Dive using PyTorch
How to measure activation memory in PyTorch, and why the choice of activation function matters.
MAY 22, 2024
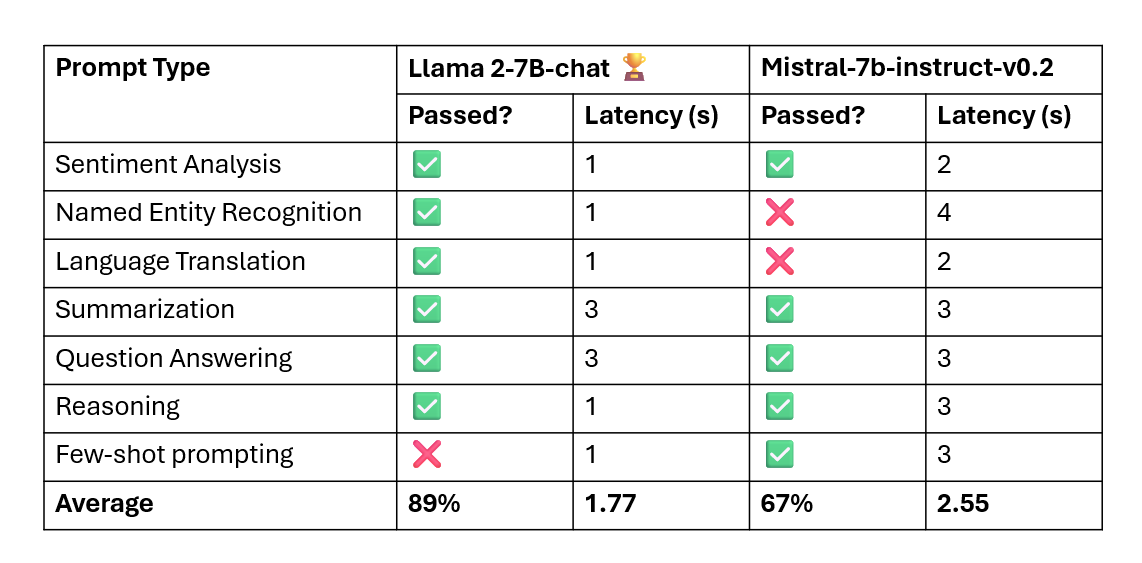
Mistral 7B vs. Llama-2 7B: Lightning Round using GenAI studio
Let’s compare how Mistral-7b-instruct-v0.2 and Llama 2-7B-chat perform on some basic LLM prompts.

MAY 15, 2024
Activation Memory: What is it?
An introduction to activation memory, and how it affects GPU memory consumption during model training.
MAY 01, 2024
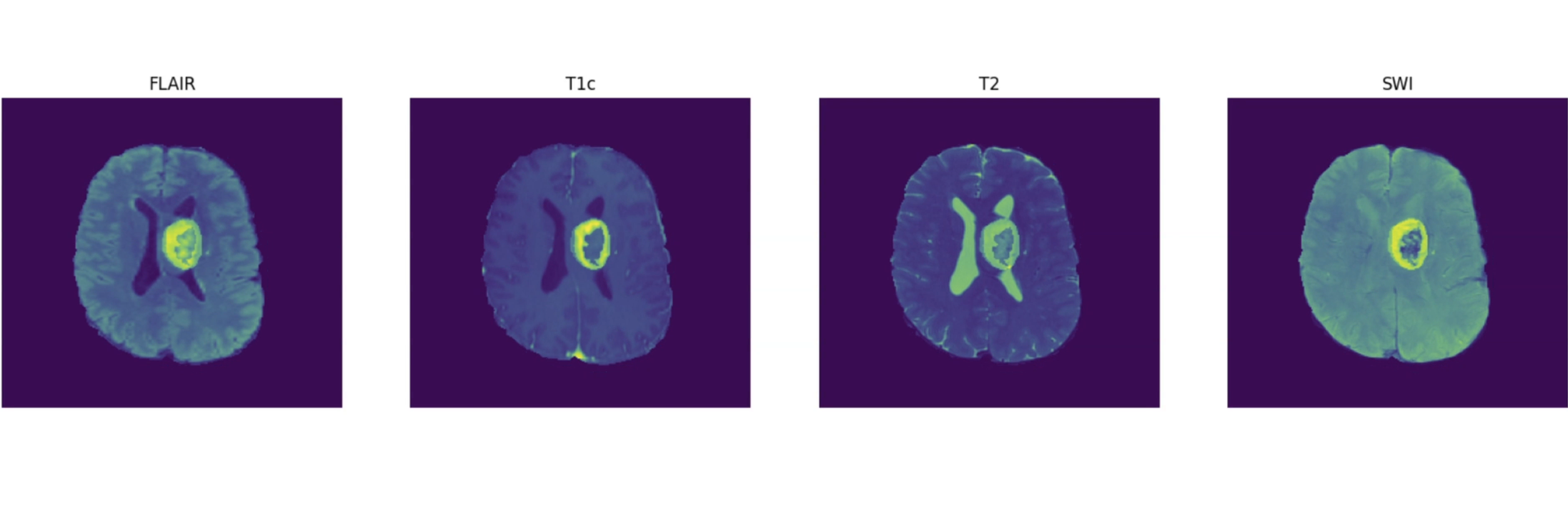
3D Diffuse Glioma Segmentation for Early Cancer Detection: Spotlight Demo
Using HPE’s AI platform to develop an early brain cancer detection machine learning model.

APR 24, 2024
From a pre-trained model to an AI assistant: Finetuning Gemma-2B using DPO
LLM Alignment using Direct Preference Optimization, an alternative to RLHF

FEB 28, 2024
Finetuning Mistral-7B with LoRA and DeepSpeed
How to Finetune Mistral-7B using HuggingFace + Determined

OCT 30, 2023
LLM Prompting: The Basic Techniques
A gentle introduction to large language model prompting methods and terminology.